
- 1 TL;DR
- 2 Introduction
- 3 Installation & Setup
- 4 Interrogating Data
- 5 Descriptives
- 6 To see, look
- 6.1 Anscombe’s lesson: numeric descriptions can be misleading
- 6.2
plot_*-ting data with elucidate- 6.2.1 basic
plot_scatter()with regression lines - 6.2.2 basic
plot_density() - 6.2.3 customized
plot_density() - 6.2.4 basic
plot_box() - 6.2.5 customized
plot_box()with facetting - 6.2.6 basic
plot_stat_error()of the mean +/- SE - 6.2.7 plot medians and bootstrapped CIs
- 6.2.8 plot means or medians and CIs for multiple time points connected with lines
- 6.2.1 basic
- 7 Interacting with dynamic data representations
- 8 Correct data with
wash_df()&recode_errors() - 9 Performance Evaluations
- 10 Navigation
- 11 Notes
1 TL;DR
This post dives into the elucidate package and how it can help you explore data using sets of functions for interrogating, describing, visualising, interacting with, and correcting data. This is a key stage of any analysis where errors are found and interesting relationships begin to appear.

2 Introduction
The 10th post of the Scientist’s Guide to R series takes us on a journey of discovery through data exploration. It’s going to be an epic journey too because of how much there is to cover. In data science, sometimes you can even learn enough in this stage of an analysis to answer basic research questions. Read on to see how straightforward exploratory data analysis (EDA) can be with a new R package I created called elucidate.
elucidate helps you explore data by making it easy and efficient to:
Interrogate data in search of anomalies with
copies(),dupes(), andcounts*.Describe data with the
describe*set of functions for obtaining summary statistics, bootstrapping confidence intervals, and detecting missing values.Quickly visualise data with the
plot_*set of functions.Interact with data representations using the
static_to_dynamic()function.Correct data entry errors, anomaly indicator values, and structural inconsistencies seen in real world data more easily using
wash_df()andrecode_errors(). Here we blur the lines a bit between transformation and EDA, because data prep is usually an iterative cleaning/exploring process in practice.
elucidate is a package I’ve been thrilled to be developing for the Research Branch of the British Columbia Ministry of Social Development & Poverty Reduction since I started working as a public servant last spring1. Although I only spend a small fraction of my time on elucidate, I’m incredibly grateful for the BC Gov’s ongoing support of the project so I can continue building it for all of us.
Inspired by tidyverse naming conventions, many elucidate function are organized into sets that begin with a common root (e.g. describe*, plot_*, counts*), since this lets you see them all as suggestions while coding in R studio after typing the first three characters of the function or object name. It also facilitates code completion via the tab key.
Many elucidate functions also accept a data frame as the 1st argument and return a data frame (or ggplot) as output, so they are compatible with the pipe operator (%>%) from the magrittr package for easy integration into “tidy” data processing pipelines. For convenience, the pipe operator is also imported from magrittr when elucidate is loaded.
Bonus! I recently saw a great twitter thread on how to capture screen recordings and include them in R markdown2 docs, so I’m going to try them out in this very post.
Disclaimer: This post covers ways of using R to get descriptive statistics, such as the sample mean, standard deviation, and skewness for numeric variables. I’m going to assume that you learned what these are and how to calculate them in an undergraduate introductory statistics course. If these terms are unfamiliar to you and/or statistics seems scary as a topic in general, I strongly recommend visiting Brown University’s awesome Seeing Theory website before proceeding.
3 Installation & Setup
Because it is still rapidly evolving, elucidate is not on CRAN yet (maybe in 2021); so you can’t install it the normal way with install.packages().
Instead, like the development versions of many other packages, you can get it from github with:
install.packages("remotes") #only run this 1st if you haven't installed remotes before
remotes::install_github("bcgov/elucidate")
#note: if you have trouble installing or updating some of the dependencies when
#installing a package from GitHub, try (re)-installing their CRAN versions (if
#available) 1st using install.packages().Then just load it like any other R package, with the library() function:
library(tidyverse) #for comparisons & the glimpse function## -- Attaching packages --------------------------------------- tidyverse 1.3.0 --## v ggplot2 3.3.3 v purrr 0.3.4
## v tibble 3.1.1 v dplyr 1.0.2
## v tidyr 1.1.2 v stringr 1.4.0
## v readr 1.4.0 v forcats 0.5.0## Warning: package 'ggplot2' was built under R version 4.0.5## Warning: package 'tibble' was built under R version 4.0.5## -- Conflicts ------------------------------------------ tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(janitor) #for comparisons##
## Attaching package: 'janitor'## The following objects are masked from 'package:stats':
##
## chisq.test, fisher.testlibrary(bench) #for benchmarking
library(elucidate)##
## Attaching package: 'elucidate'## The following object is masked from 'package:base':
##
## mode#also set the random generator seed for reproducibility
set.seed(1234)For this post, we’ll use the generated dataset, pdata (short for practice data), that is imported with elucidate.
4 Interrogating Data
As usual, we’ll start by inspecting the structure of it with dplyr::glimpse().
glimpse(pdata)## Rows: 12,000
## Columns: 10
## $ id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18~
## $ d <date> 2008-01-01, 2008-01-01, 2008-01-01, 2008-01-01, 2008-01-01, ~
## $ g <fct> e, c, d, c, a, a, d, b, e, c, a, a, a, a, a, b, c, b, a, c, a~
## $ high_low <chr> "high", "high", "low", "high", "high", "high", "low", "low", ~
## $ even <lgl> FALSE, TRUE, FALSE, TRUE, FALSE, TRUE, FALSE, TRUE, FALSE, TR~
## $ y1 <dbl> 106.26334, 96.47998, 99.33155, 108.94097, 99.65422, 101.59775~
## $ y2 <dbl> 117.92654, 107.16036, 96.16405, 101.78278, 113.36807, 113.586~
## $ x1 <int> 59, 5, 71, 60, 96, 19, 77, 74, 92, 4, 56, 100, 69, 44, 91, 35~
## $ x2 <int> 116, 101, 111, 130, 196, 163, 133, 191, 106, 134, 142, 111, 1~
## $ x3 <int> 248, 238, 250, 287, 284, 206, 201, 249, 277, 209, 285, 277, 2~This tells us that we’ve got 12,000 rows and 10 columns of various classes to work with including an “id” and date (“d”) column that could represent distinct observations.
Instead of 12,000 rows, let’s over-sample it with replacement so that there are 1,000,000 rows to allow the performance of elucidate functions to be more realistically evaluated.
pdata_resampled <- pdata[sample(1:nrow(pdata), 1e6, replace = TRUE),]
dim(pdata_resampled) ## [1] 1000000 104.1 checking for row copies() and dupes()
dplyr::glimpse() is a great first step in the data interrogation process. After learning about the columns names classes, dimensions, and previewing some of the data, the next thing I usually check is how many copies I have of each row based on columns like subject ID # and date, where I’m hoping that there are as many copies as I should find (i.e. one row per ID and date combination, representing unique measurements). Usually this means making sure there aren’t any unexpected row duplicates. This can easily be checked with elucidate::copies().
pdata_resampled %>%
copies() %>%
glimpse() #glimpse() again to show all output columns## No column names specified - using all columns.## Rows: 1,000,000
## Columns: 12
## $ id <int> 452, 16, 162, 86, 269, 196, 623, 885, 934, 948, 146, 367, ~
## $ d <date> 2015-01-01, 2016-01-01, 2015-01-01, 2016-01-01, 2015-01-0~
## $ g <fct> d, b, e, c, a, e, c, d, d, d, b, c, c, a, c, a, c, a, d, e~
## $ high_low <chr> "high", "high", "low", "high", "high", "low", "low", "low"~
## $ even <lgl> TRUE, TRUE, TRUE, TRUE, FALSE, TRUE, FALSE, FALSE, TRUE, T~
## $ y1 <dbl> 195.22487, 196.53225, 117.96544, 228.54892, 144.27335, 134~
## $ y2 <dbl> 104.22839, 108.96997, 92.46506, 108.54791, 107.09374, 95.1~
## $ x1 <int> 49, 34, 72, 78, 36, 35, 32, 43, 55, 85, 33, 84, 85, 44, 52~
## $ x2 <int> 196, 142, 181, 105, 190, 181, 108, 161, 111, 199, 191, 183~
## $ x3 <int> 254, 295, 286, 244, 202, 260, 280, 284, 233, 254, 267, 222~
## $ copy_number <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1~
## $ n_copies <int> 77, 72, 82, 88, 98, 105, 76, 69, 78, 87, 92, 80, 85, 85, 9~You can see that the default version of copies() simply returns the input data with the addition of two columns called “copy_number” (which copy the rows is if multiple copies were detected) and “n_copies” (total number of row copies detected)3.
In this case, I’ve resampled the same data quite a lot, so there are multiple copies of all original rows. copies() will also preserve the original ordering of the rows unless you ask it to sort the output by the number of copies4. You do so by setting the sort_by_copies argument to TRUE. If you also only want to see duplicated rows, you can set the filter argument to “dupes”5.
pdata_resampled %>%
copies(filter = "dupes", sort_by_copies = TRUE)## No column names specified - using all columns.## Duplicated rows detected! 1000000 of 1000000 rows in the input data have multiple copies.## # A tibble: 1,000,000 x 11
## id d g high_low even y1 y2 x1 x2 x3 n_copies
## <int> <date> <fct> <chr> <lgl> <dbl> <dbl> <int> <int> <int> <int>
## 1 546 2016-01-01 d high TRUE 221. 104. 81 122 226 119
## 2 546 2016-01-01 d high TRUE 221. 104. 81 122 226 119
## 3 558 2016-01-01 e high TRUE 149. 107. 63 134 223 119
## 4 558 2016-01-01 e high TRUE 149. 107. 63 134 223 119
## 5 546 2016-01-01 d high TRUE 221. 104. 81 122 226 119
## 6 546 2016-01-01 d high TRUE 221. 104. 81 122 226 119
## 7 546 2016-01-01 d high TRUE 221. 104. 81 122 226 119
## 8 558 2016-01-01 e high TRUE 149. 107. 63 134 223 119
## 9 558 2016-01-01 e high TRUE 149. 107. 63 134 223 119
## 10 546 2016-01-01 d high TRUE 221. 104. 81 122 226 119
## # ... with 999,990 more rowsAs the message informed us, by default copies() will check for duplicates based on all columns unless you specify columns to condition the search upon. This is done by simply listing the unquoted names of the columns. E.g. to check for copies based on just the “id” and “d” (date) columns. This time we’ll use the original version of pdata, to see if each combination of the id and d columns do in fact represents distinct observations…
pdata %>%
copies(id, d, #only consider these columns when searching for copies
#only return the rows with at least one duplicate
filter = "dupes",
#sort the result by the number of copies and then specified
#conditioning variables (in the same order specified).
sort_by_copies = TRUE)## No duplicates detected.## # A tibble: 0 x 11
## # ... with 11 variables: id <int>, d <date>, g <fct>, high_low <chr>,
## # even <lgl>, y1 <dbl>, y2 <dbl>, x1 <int>, x2 <int>, x3 <int>,
## # n_copies <int># note: if you didn't specify any conditioning variables, sort_by_copies will
# only cause copies() to sort the output by the n_copies column…and they do 😄.
Checking for duplicates and sorting the result like this is by far the most common way to use copies(), so elucidate version 0.0.0.9023 also introduced a convenience wrapper function for the above called dupes():
copies_result <- pdata %>% copies(id, d, filter = "dupes", sort_by_copies = TRUE)
dupes_result <- pdata %>% dupes(id, d)
identical(copies_result, dupes_result)## [1] TRUESince the extra copies in the resampled version of the data are meaningless, if this were a real dataset intended for research purposes we would probably want to get rid of them and just keep the 1st copy of each to end up with a distinct6 set of rows. This can also be achieved with copies() by instead setting the filter argument to “first” (or “last” for the last copy). In this situation, we actually recover a data frame that is equivalent to the original version of pdata, as demonstrated using identical() after some sorting and reformatting.
pdata_distinct <- pdata_resampled %>% #the resampled 1,000,000 row version
copies(filter = "first") %>% #only keep the 1st detected copy of each row
arrange(id, d, g, high_low, even, y1, y2, x1, x2, x3) %>%
wash_df()## No column names specified - using all columns.pdata_sorted <- pdata %>% #original data that has not been resampled
arrange(id, d, g, high_low, even, y1, y2, x1, x2, x3) %>%
wash_df()
pdata_distinct %>% glimpse## Rows: 12,000
## Columns: 10
## $ id <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2~
## $ d <date> 2008-01-01, 2009-01-01, 2010-01-01, 2011-01-01, 2012-01-01, ~
## $ g <chr> "e", "e", "e", "e", "e", "e", "e", "e", "e", "e", "e", "e", "~
## $ high_low <chr> "high", "low", "high", "low", "low", "low", "low", "low", "lo~
## $ even <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE~
## $ y1 <dbl> 106.26334, 110.03424, 157.88571, 110.80402, 134.40024, 158.24~
## $ y2 <dbl> 117.92654, 90.61188, 106.97367, 99.20771, 96.22263, 94.98052,~
## $ x1 <dbl> 59, 14, 14, 69, 93, 26, 47, 79, 19, 87, 75, 86, 5, 73, 25, 86~
## $ x2 <dbl> 116, 186, 141, 186, 193, 149, 180, 197, 196, 135, 172, 199, 1~
## $ x3 <dbl> 248, 238, 243, 256, 216, 277, 232, 251, 293, 261, 287, 261, 2~identical(pdata_distinct, pdata_sorted)## [1] TRUEHere the dplyr::arrange() and elucidate::wash_df() steps only serve to standardize the formatting/order of the data without modifying any of the actual values. There will be more about wash_df() later. Now you also know how to eliminate row duplicates and recover data that has been oversampled. When working with real data, this issue most commonly occurs when a join goes awry. In fact, I strongly recommend checking for duplicates and filtering them if appropriate both before and after every join, at least the first time you’re trying to combine two datasets. copies() can help you with both tasks.
Real world relevance - Not long ago I was examining medical records and expected to see one record per person per visit to a health care provider. I was surprised to learn that in fact the data contained one row per service provided, with multiple rows per visit. Checking for duplicates using copies() revealed this important structural aspect of the data, which subsequently determined how I prepared it for analysis.
4.2 count()-ing unique values
The counts* set of functions helps you quickly check your data for manual entry errors or weird values by providing counts of unique values. In my experience, such errors tend to show up as very rare or common values.
counts() returns the unique values and counts for a vector in the form “value_count”, sorted by decreasing frequency7.
counts(pdata_resampled$g)## [1] "a_216058" "b_205319" "d_197784" "e_196104" "c_184735"#use order = "a" or "i" to sort in ascending/increasing ordercounts_all() gives you a list of unique values and their frequency for all columns in a data frame. To avoid printing too much here, we’ll first select a few columns to show you what the output looks like.
pdata_resampled %>%
select(d, high_low, even) %>%
counts_all()## $d
## [1] "2012-01-01_83846" "2015-01-01_83674" "2018-01-01_83667" "2010-01-01_83558"
## [5] "2017-01-01_83385" "2019-01-01_83372" "2014-01-01_83335" "2011-01-01_83114"
## [9] "2009-01-01_83024" "2008-01-01_83013" "2016-01-01_83009" "2013-01-01_83003"
##
## $high_low
## [1] "high_504860" "low_495140"
##
## $even
## [1] "TRUE_500662" "FALSE_499338"For convenience, elucidate also provides shortcut functions counts_tb() and counts_tb_all() that give you the top and bottom “n” unique values (“n” is up to 10 by default) in terms of frequency. Here we’ll just ask for the top 5 and bottom 5 values.
pdata_resampled %>%
select(d, high_low, even) %>%
counts_tb_all(n = 5)## $d
## top_v top_n bot_v bot_n
## 1 2012-01-01 83846 2013-01-01 83003
## 2 2015-01-01 83674 2016-01-01 83009
## 3 2018-01-01 83667 2008-01-01 83013
## 4 2010-01-01 83558 2009-01-01 83024
## 5 2017-01-01 83385 2011-01-01 83114
##
## $high_low
## top_v top_n bot_v bot_n
## 1 high 504860 low 495140
## 2 low 495140 high 504860
## 3 <NA> <NA> <NA> <NA>
## 4 <NA> <NA> <NA> <NA>
## 5 <NA> <NA> <NA> <NA>
##
## $even
## top_v top_n bot_v bot_n
## 1 TRUE 500662 FALSE 499338
## 2 FALSE 499338 TRUE 500662
## 3 <NA> <NA> <NA> <NA>
## 4 <NA> <NA> <NA> <NA>
## 5 <NA> <NA> <NA> <NA>This time we get a list of tibbles instead of a list of vectors, with the top values (“top_v”) and their counts (“top_n”) as a pair of columns, and the bottom values (“bot_v”) beside their counts (“bot_n”). You may have noticed that in cases where there are fewer than “n” unique values, all of them will be shown under each of the top_* and bot_* columns, albeit in opposite orders. As expected, counts_tb() gives you a single tibble showing the top and bottom counts for a single column.
Using the mark() function from the bench package (i.e. bench::mark()), we can see that these functions run reasonably fast on even 1,000,000 rows of data; under 10 seconds on my laptop (Intel i7-9750H processor @2.6 GHz with 16GB of RAM).
mark(
#just wrap the expression you want to evaluate the performance of with the
#bench::mark() function
pdata_resampled %>%
select(d, high_low, even) %>%
counts_tb_all(),
#specify the number of iterations to use for benchmarking with the iterations
#argument
iterations = 10) %>%
#subset the output to just get the timing & memory usage info
select(median)## Warning: Some expressions had a GC in every iteration; so filtering is disabled.## # A tibble: 1 x 1
## median
## <bch:tm>
## 1 9.69sNow you know how easy it can be to check for data entry errors with the counts* set of elucidate functions.
The latest version of elucidate also includes a mode()8 function which returns just the most common value (i.e. the mode) of any vector.
4.3 describe()-ing missingness & extreme values
Checking for other anomalies like extreme values (outliers) and missing values can be achieved with describe(). To start with, we’ll subset the output to just focus on columns relevant these quality indicators.
pdata_resampled %>%
describe(y1) %>%
#desctibe() outputs a tibble, which means we can subsequently manipulate the
#output with dplyr functions, like select()
select(cases:p_na, p0:p100) ## # A tibble: 1 x 9
## cases n na p_na p0 p25 p50 p75 p100
## <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1000000 1000000 0 0 69.2 121. 145. 181. 289.From this subset of the output alone we can tell that there are no missing values for y1, which ranges from a minimum (p0) of 69 to a maximum (p100) of 289.2. If p0 is less than ~1.5 x the interquartile range (p75-p25) away from p25 (= 25th percentile) or p100 is >1.5 x IQR greater than p75 (= 75th percentile), we might be concerned about possible outliers in the data. However, unless the deviation is really obvious, you’re better off just looking at a box plot (basically gets you the same information much faster) using elucidate::plot_box(). If you happen to know a priori what the normal range of the dependent variable is you can just check the minimum and maximum values for potential outliers.
Data entry errors can show up here as extreme deviations, like a maximum value of 2,892 or a minimum value of -500 would be in this case. You should also check to see if most of the percentiles are very close to the same value, which could indicate the presence of ceiling effects or floor effects in the dependent variable9.
Another thing to keep in mind is that some data collection protocols use codes like “9999” (when most true values are < 100) to represent invalid responses (e.g. the patient refused to answer the question) or a specific reason data are missing (e.g. equipment failures). If possible, you should check for those sorts of details in any available protocol documents or other metadata that exist for the data you’re using.
5 Descriptives
5.1 describe() a vector with summary statistics
To get a descriptive summary of a vector you could use the base R summary() function, which is very fast but yields rather limited information. For numeric vectors, summary() will give you the minimum, mean, median, 25th percentile, 75th percentile, and maximum values. It will also tell you how many NA’s there are, but only if some are detected (and not for non-numeric vectors). Alternatively, we can use describe() to get most (or all) of the summary statistics we typically want.10
pdata_resampled$y1 %>% summary()## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 69.22 120.94 144.75 153.74 181.08 289.24describe(data = pdata_resampled,
#if data is a data frame, then you specify the column to describe using
#the 2nd argument "y"
y = y1,
#you can output the results as a data.table instead of a tibble
#(default is "tibble") so all output is printed
output = "dt")## cases n na p_na mean sd se p0 p25 p50 p75
## 1: 1000000 1000000 0 0 153.742 42.734 0.043 69.224 120.942 144.75 181.079
## p100 skew kurt
## 1: 289.235 0.74 -0.183#equivalently, describe(pdata_resampled$y1, output = "dt")In addition to everything provided by summary(), describe() also gives us the standard deviation, standard error of the mean, and clearer information on the shape of the distribution via skewness = “skew” and (excess-)kurtosis = “kurt”, where values of either > 1 or < -1 indicate non-trivial deviations from normality. In such cases you might want to use the median (p50) and as a measure of central tendency rather than the mean, and the interquartile range (p75-p25) as a measure of the spread of values instead of the standard deviation or standard error. You may also want to look at the distribution with one of the plot_* functions covered below. elucicidate also provides convenience wrappers for the skewness() and kurtosis() functions in the e1071 (and other) packages if you want just these measures for a numeric vector11.
We also get information on the presence of missing values, as highlighted previously.
5.2 grouped descriptions
Experimental research typically focuses on group comparisons (i.e. intervention vs. control), which was a key consideration in developing elucidate. Where possible, elucidate functions make it easy for you to incorporate grouping variables. For example, you can specify any number of them in the describe* functions as unquoted column names via the special ... argument. For example, to summarise the “y1” numeric variable in pdata for each level of the factor g, we just use:
pdata_resampled %>%
#1st column name is passed to the y argument to indicate the variable to be
#described
describe(y1,
#subsequent unquoted column names are interpreted as grouping
#variables
g)## # A tibble: 5 x 15
## g cases n na p_na mean sd se p0 p25 p50 p75
## <fct> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 d 197784 197784 0 0 174. 43.8 0.098 69.2 138. 175. 214.
## 2 b 205319 205319 0 0 152. 37.8 0.083 74.4 118. 146. 188.
## 3 e 196104 196104 0 0 135. 18.6 0.042 75.1 123. 137. 148.
## 4 c 184735 184735 0 0 177. 57.0 0.133 77.0 127. 166. 232.
## 5 a 216058 216058 0 0 134. 25.8 0.055 75.9 112. 133. 156.
## # ... with 3 more variables: p100 <dbl>, skew <dbl>, kurt <dbl>#or more compactly: describe(pdata, y1, g)It’s really that easy.
5.3 describe_all() columns in a data frame
What if you want to describe all columns of a data frame? What about such a description for each level of one or more grouping variables? This is what describe_all() does.
To describe a subset of variables instead of all of them, just pass the data through dplyr::select() before piping it to describe_all().
pdata_resampled %>%
#for the sake of brevity we'll just pick one of each major class to
#demonstrate class-specific results that are provided
select(d, g, high_low, even, y2, x1) %>%
describe_all()## $date
## # A tibble: 1 x 8
## variable cases n na p_na n_unique start end
## <chr> <int> <int> <int> <dbl> <int> <date> <date>
## 1 d 1000000 1000000 0 0 12 2008-01-01 2019-01-01
##
## $factor
## # A tibble: 1 x 8
## variable cases n na p_na n_unique ordered counts_tb
## <chr> <int> <int> <int> <dbl> <int> <lgl> <chr>
## 1 g 1e6 1e6 0 0 5 FALSE a_216058, b_205319, ..., ~
##
## $character
## # A tibble: 1 x 9
## variable cases n na p_na n_unique min_chars max_chars counts_tb
## <chr> <int> <int> <int> <dbl> <int> <int> <int> <chr>
## 1 high_low 1e6 1e6 0 0 2 3 4 high_504860, ~
##
## $logical
## # A tibble: 1 x 8
## variable cases n na p_na n_TRUE n_FALSE p_TRUE
## <chr> <int> <int> <int> <dbl> <dbl> <dbl> <dbl>
## 1 even 1000000 1000000 0 0 500662 499338 0.501
##
## $numeric
## # A tibble: 2 x 15
## variable cases n na p_na mean sd se p0 p25 p50 p75
## <chr> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 y2 1000000 1000000 0 0 100. 10.1 0.01 60.0 93.4 100. 107.
## 2 x1 1000000 1000000 0 0 50.6 28.9 0.029 1 25 50 76
## # ... with 3 more variables: p100 <dbl>, skew <dbl>, kurt <dbl>Despite the number of calculations and operations that need to be performed, describe_all() also runs pretty quickly for this amount of data, taking a second and using less than 620 MB of RAM to describe 6 columns of various classes with 1,000,000 values each12.
mark(
pdata_resampled %>%
select(d, g, high_low, even, y2, x1) %>%
describe_all(),
iterations = 10
) %>%
select(median,
#bench::mark() also tells us how much memory was used
mem_alloc)## Warning: Some expressions had a GC in every iteration; so filtering is disabled.## # A tibble: 1 x 2
## median mem_alloc
## <bch:tm> <bch:byt>
## 1 998ms 619MBAgain, you can specify any number of grouping variables as unquoted column names that are present in the input data via the .... You can also selectively describe variables of specific classes using describe_all()’s “class” argument, which accepts a character vector of options:
- “d”: dates
- “f”: factors
- “c”: character
- “l”: logical
- “n”: numeric
- “all”: shortcut for all of the above & syntactically equivalent to c(“d”, “f”, “c”, “l”, “n”)
This can save you time both by avoiding a dplyr::select(where()) layer sometimes and also in terms of execution time (especially on larger datasets), because no unnecessary operations are performed upon columns of non-requested classes.
pdata_resampled %>%
select(-id) %>%
describe_all(g, d, #group by factor variable "g" and date variable "d"
class = "n") #only describe numeric variables other than the id column## # A tibble: 300 x 17
## g d variable cases n na p_na mean sd se p0
## <fct> <date> <chr> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 d 2015-01-01 y1 16606 16606 0 0 199. 11.5 0.089 172.
## 2 d 2015-01-01 y2 16606 16606 0 0 99.5 9.56 0.074 73.4
## 3 d 2015-01-01 x1 16606 16606 0 0 54.0 28.4 0.22 1
## 4 d 2015-01-01 x2 16606 16606 0 0 151. 26.8 0.208 101
## 5 d 2015-01-01 x3 16606 16606 0 0 250. 30.6 0.237 201
## 6 b 2016-01-01 y1 17099 17099 0 0 185. 11.1 0.085 150.
## 7 b 2016-01-01 y2 17099 17099 0 0 101. 10.2 0.078 74.4
## 8 b 2016-01-01 x1 17099 17099 0 0 51.4 30.0 0.229 2
## 9 b 2016-01-01 x2 17099 17099 0 0 149. 28.9 0.221 101
## 10 b 2016-01-01 x3 17099 17099 0 0 253. 29.9 0.228 201
## # ... with 290 more rows, and 6 more variables: p25 <dbl>, p50 <dbl>,
## # p75 <dbl>, p100 <dbl>, skew <dbl>, kurt <dbl>#performance when splitting by 2 variables.
mark(
pdata_resampled %>% select(-id) %>%
describe_all(g, d, class = "n"),
iterations = 10) %>%
select(median, mem_alloc)## Warning: Some expressions had a GC in every iteration; so filtering is disabled.## # A tibble: 1 x 2
## median mem_alloc
## <bch:tm> <bch:byt>
## 1 1.59s 994MBNote that if only one description variable class is requested, you’ll get a data frame back instead of a list of data frames. Moreover, despite having to repeat all calculations across the 5 non-id numeric columns in the 1,000,000 row version of pdata for each of 5 levels of the g factor, we get all of the results in ~1.6 seconds using ~1 GB of RAM!
5.4 confidence intervals
Confidence intervals are a topic that students (and some seasoned researchers) tend to struggle with, so I’ll cover it here in more detail. In frequentist inference, a confidence interval (CI) provides an estimate of the possible values a statistic (AKA “parameter”), such as the mean, could take in the population based on the distribution of values in the observed sample data. It is basically an educated guess about what the population value for the parameter is, based on the observed evidence. Naturally, the more observations you have to work with, the more precise your estimates will be. More concretely, an observed 95% CI for a mean of 1-5 has a 95% probability of containing the true population mean.
Bootstrapping13 is a computational procedure to estimate the sampling distribution for the statistic of interest by sampling from the observed data with replacement and calculating the statistic for each sample. This process is repeated thousands of times, and the observed probability distribution of (re-)sampled statistics is used to define confidence limits for plausible values of the statistic in the underlying population. CIs are difficult to derive analytically for statistics other than the mean, but modern computers make it no trouble at all to use bootstrapping to estimate them.
In practice, we often estimate a statistic, like the mean, based on a single sample under the assumption that the true probability distribution of what we are measuring closely approximates a well defined distribution in the exponential family, such as the “normal” (AKA “Gaussian”) distribution for continuous variables. In behavioural research, this “normality” assumption is often reasonable because most psychological traits (e.g. intelligence) tend to be expressed in an approximately normally distributed fashion (e.g. performance on IQ tests). Interestingly, it is also generally reasonable for large sample sizes, due to the central limit theorem (CLT). The CLT teaches us that a mean estimated from a sufficiently large random sample of independent and identically distributed values (often abbreviated as “i.i.d.”)14 will be approximately normally distributed irrespective of the shape of the distribution of values in the underlying population. You can see the CLT in action here, which is the best demonstration of it I’ve come across so far. You can typically benefit from the CLT if you have a sample size >= 30, which means that you don’t need to worry as much about violations of normality for large samples as they pertain to the validity of popular tests like the analysis of variance.
elucidate helps you get either theory-based CIs for the mean or bootstrapped CIs for other numeric variable summary statistics using the describe_ci() and describe_ci_all() functions.
These functions are also super easy to use. They both return a tibble, with a column indicating the “lower” bound of the CI, the observed statistic, and the “upper” bound of the CI. By default, you’ll get a 95% CI for the mean derived analytically from a normal distribution.
Generating CIs can take a while for larger vectors especially when bootstrapping is involved, so for this segment of the post we’ll work with the original 12,000-row version of pdata.
pdata %>%
describe_ci(y1)## # A tibble: 1 x 3
## lower mean upper
## <dbl> <dbl> <dbl>
## 1 153. 154. 154.To get a CI for another statistic, you set the “stat” argument to the unquoted name of the summary statistic function. For example, to get a 95% CI for the median of y1, we can use:
pdata %>%
describe_ci(y1, stat = median)## # A tibble: 1 x 3
## lower median upper
## <dbl> <dbl> <dbl>
## 1 144. 145. 146.The CIs for summary statistics other than the mean are obtained using bootstrapping via the boot package that is installed with R. You can modify some key bootstrapping parameters, like the number of replicates or the type of CIs to return, via some additional arguments. Like describe(), describe_ci() also accepts any number of unquoted variable names to use as grouping variables via .... You can also try to speed things up with parallel processing if you have multiple cores on your machine15.
pdata %>%
describe_ci(y1,
g, #get the median and bootstrapped CI of y1 for each level of g
stat = median,
#use 5,000 bootstrap replicates instead of the default 2,000
replicates = 5000,
#get a bias-corrected and accelerated CI instead of the default
#percentile intervals
ci_type = "bca",
#you can adjust the confidence level via ci_level
ci_level = 0.9,
#you can enable parallel processing if you have multiple cores
parallel = TRUE,
#specify the number of cores to use with the cores argument
#my laptop has 12 logical cores so I'll use 10 of them
cores = 10)## # A tibble: 5 x 4
## g lower median upper
## <fct> <dbl> <dbl> <dbl>
## 1 a 131. 133. 134.
## 2 b 141. 147. 152.
## 3 c 159. 165. 172.
## 4 d 170. 175. 180.
## 5 e 136. 137. 137.It is worth noting that adding more cores doesn’t necessarily mean things will end up finishing sooner, due to the overhead of coordinating operations across cores.
describe_ci_all() gives you confidence intervals for the specified statistic for all numeric columns in the input data frame.
pdata %>%
select(-id) %>%
#mean and estimated CI for the mean for each non-id numeric column and each
#level of g
describe_ci_all(g) %>%
print(n = Inf) #print all rows## # A tibble: 25 x 5
## variable g lower mean upper
## <chr> <fct> <dbl> <dbl> <dbl>
## 1 x1 e 49.5 50.7 51.8
## 2 x1 c 48.7 49.9 51.1
## 3 x1 d 49.4 50.5 51.7
## 4 x1 a 50.2 51.3 52.4
## 5 x1 b 48.8 50.0 51.1
## 6 x2 e 150. 151. 152.
## 7 x2 c 149. 150. 151.
## 8 x2 d 150. 151. 152.
## 9 x2 a 150. 151. 153.
## 10 x2 b 149. 150. 151.
## 11 x3 e 249. 250. 251.
## 12 x3 c 250. 251. 252.
## 13 x3 d 249. 250. 251.
## 14 x3 a 249. 250. 251.
## 15 x3 b 250. 251. 252.
## 16 y1 e 134. 135. 136.
## 17 y1 c 175. 177. 180.
## 18 y1 d 172. 174. 176.
## 19 y1 a 133. 134. 135.
## 20 y1 b 150. 152. 153.
## 21 y2 e 99.7 100. 101.
## 22 y2 c 99.5 99.9 100.
## 23 y2 d 99.7 100. 100.
## 24 y2 a 99.7 100. 100.
## 25 y2 b 99.8 100. 101.This reveals that all groups of the “g” factor in pdata probably have similar population mean values and are unlikely to represent statistically different populations in terms of the “x1”, “x2”, “x3”, or “y2” variables (because the 95% CIs for the mean of each group overlap with one another). However, the mean “y1” scores of groups “c” & “d” seem to be higher than the means of groups “a”, “b”, & “e”. These results suggest that “y1” is a useful measure for differentiating between some of the “g” factor groups in pdata.
6 To see, look
6.1 Anscombe’s lesson: numeric descriptions can be misleading
Anscombe’s famous quartet revealed that we can’t always rely upon a set of summary statistics to learn all of the key features of our data. The quartet is a set of four pairs of variables with nearly identical summary statistic values & linear regression parameters but very different distributions. Since these data come pre-loaded with base R, we can just use them (like mtcars) by calling the name anscombe. There are 4 pairs (numbered 1-4) of x and y variables to be examined.
We’ll first examine these data using describe_all().
anscombe %>%
#recall that glimpse doesn't modify the data itself, so we can use it in the
#middle of a pipeline
glimpse() %>%
describe_all() %>%
select(mean:kurt)## Rows: 11
## Columns: 8
## $ x1 <dbl> 10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5
## $ x2 <dbl> 10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5
## $ x3 <dbl> 10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5
## $ x4 <dbl> 8, 8, 8, 8, 8, 8, 8, 19, 8, 8, 8
## $ y1 <dbl> 8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68
## $ y2 <dbl> 9.14, 8.14, 8.74, 8.77, 9.26, 8.10, 6.13, 3.10, 9.13, 7.26, 4.74
## $ y3 <dbl> 7.46, 6.77, 12.74, 7.11, 7.81, 8.84, 6.08, 5.39, 8.15, 6.42, 5.73
## $ y4 <dbl> 6.58, 5.76, 7.71, 8.84, 8.47, 7.04, 5.25, 12.50, 5.56, 7.91, 6.89## # A tibble: 8 x 10
## mean sd se p0 p25 p50 p75 p100 skew kurt
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 9 3.32 1 4 6.5 9 11.5 14 0 -1.2
## 2 9 3.32 1 4 6.5 9 11.5 14 0 -1.2
## 3 9 3.32 1 4 6.5 9 11.5 14 0 -1.2
## 4 9 3.32 1 8 8 8 8 19 3.32 11
## 5 7.50 2.03 0.613 4.26 6.32 7.58 8.57 10.8 -0.065 -0.535
## 6 7.50 2.03 0.613 3.1 6.70 8.14 8.95 9.26 -1.32 0.846
## 7 7.5 2.03 0.612 5.39 6.25 7.11 7.98 12.7 1.86 4.38
## 8 7.50 2.03 0.612 5.25 6.17 7.04 8.19 12.5 1.51 3.15The means, standard deviations, and standard errors we get suggest that all of the x variables and y variables are quite similar to one another, although the percentiles and skew/kurtosis columns hint that perhaps this isn’t quite true.
6.2 plot_*-ting data with elucidate
The best way to know for sure is to look at the data, in this case with scatter plots (for combinations of continous variables). R allows you do plot data in a variety of ways, but for now we’ll focus on the elucidate::plot_* function set. Each of these accepts a data frame as the 1st argument for compatibility with the pipe operator (%>%) . plot_scatter() gives us scatter plots. Required arguments are:
- data = data frame containing the x and y variables
- y = variable to plot on the y-axis
- x = variable to plot on the x-axis
We can also opt to add regression lines using the “regression_line” argument, and to get a linear regression line, we’ll set the “regression_method” argument to “lm” (for linear model). There is also an option to specify the “regression_formula” (more on this in a later post), but if you don’t use it the function will conveniently16 tell you which formula is being used by default.
N.B. There are quite a few other plot_scatter() arguments to facilitate customization. You can learn about them via ?plot_scatter().
The gridExtra package provides a helpful function called grid.arrange() that we can use to combine plots into one graphics window/printout as panels.
6.2.1 basic plot_scatter() with regression lines
p1 <- anscombe %>%
plot_scatter(y = y1, x = x1,
regression_line = TRUE, regression_method = "lm")
p2 <- anscombe %>%
plot_scatter(y = y2, x = x2,
regression_line = TRUE, regression_method = "lm")
p3 <- anscombe %>%
plot_scatter(y = y3, x = x3,
regression_line = TRUE, regression_method = "lm")
p4 <- anscombe %>%
plot_scatter(y = y4, x = x4,
regression_line = TRUE, regression_method = "lm")
#since I'm only planning to use grid.arrange() once, I'll just call it via the
#pacakge::function() syntax, which lets you access any object (yes, R functions
#are objects) from any package that you have installed without loading the rest
#of the package,
gridExtra::grid.arrange(p1, p2,
p3, p4,
#provide unquoted plot object names to be included
ncol = 2) #specify ncol or nrow## `geom_smooth()` using formula 'y ~ x'
## `geom_smooth()` using formula 'y ~ x'
## `geom_smooth()` using formula 'y ~ x'
## `geom_smooth()` using formula 'y ~ x'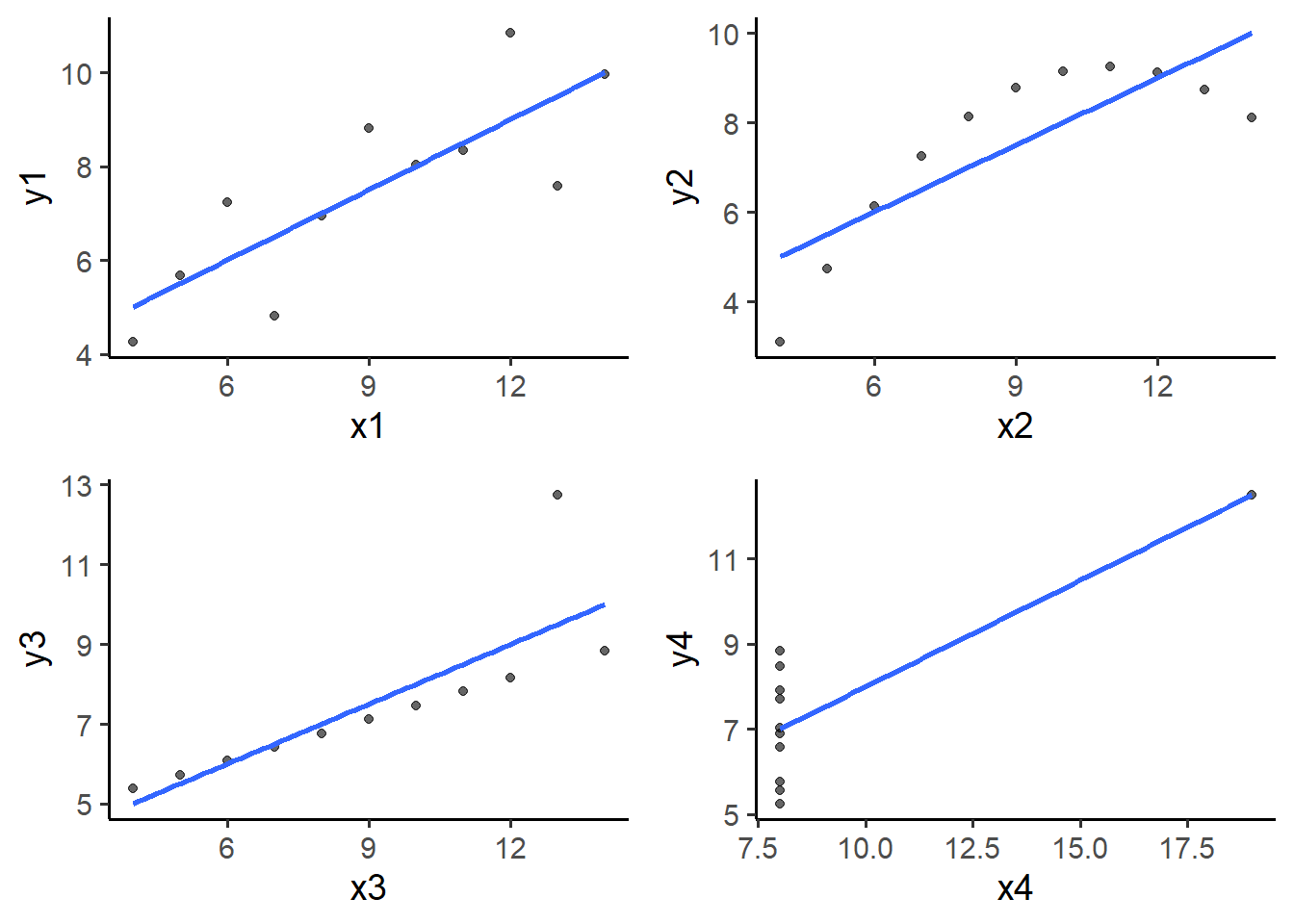
I think you’ll agree that these variable combinations are quite a bit different than we might have expected based solely on the descriptive stats! Also, basic linear regression only seems like an appropriate choice for the top left plot comparing y1 to x1. I hope you now have a better appreciation of the value of plotting data as well as the utility of metrics like skewness and kurtosis.
Other obviously named plot_* (think “plot_geometry”) convenience functions currently provided17 by elucidate include:
plot_histogram()= histogram of the binned counts of a continuous variable on the x axis (y is not supplied for this one).plot_density()= basically a smoothed version of the histogram that shows a kernel density estimate of the probability density function for a continuous variable. I tend to prefer this over the histogram because it is easier to overlay a normal distribution over it (both are on the same “probability density” scale).plot_box()= “box-and-whiskers” plot of a continuous variable on the y axis by one or more groups (a nominal variable) on the x axis. As you are hopefully already aware, this shows you the 25th, 50th (i.e. the median), and 75th percentiles for the y-variable as a box with a line through it plus whiskers extending above the 75th percentile to the maximum value (or 1.5 x the IQR) and below the 25th percentile to the minimum value.plot_violin()= violin plot of a continuous variable on the y axis by one or more groups (a nominal variable) on the x axis. Violin plots can reveal the presence of a bimodal distribution (containing multiple density peaks), which isn’t captured in a box plot.plot_stat_error()= plot a summary statistic (via the “stat” argument) for a numeric variable, and error bars (via the “error” argument) representing a measure of uncertainty in it. You can use this to quickly plot the mean +/- standard error or a confidence interval. The other “stat” option currently available is “median”.
The 4 plot types I tend to use most often in my research are the density plot, box-and-whiskers plot, scatter plot (as above), and statistic +/- error bars plot, so for this post I will focus on examples for the remaining 3 we haven’t covered so far.
6.2.2 basic plot_density()
pdata_resampled %>%
plot_density(x = y1,
title = "basic density plot",
fill = "blue2")
6.2.3 customized plot_density()
pdata %>% plot_density(x = y1,
fill_var = g, #assign a variable to colour
alpha = 0.4,
fill_var_order = c( "c", "a", "b", "d", "e"), #reorder the levels of the colour variable
fill_var_labs = c("control" = "c",
"treatment A" = "a",
"treatment B" = "b",
"treatment D" = "d",
"treatment E" = "e"), #recode the colour variable labels
fill_var_values = c("blue3",
"red3",
"green3",
"purple3",
"gold3"), #change the colours from the ggplot2 defaults
fill_var_title = "# cylinders") +
#the plot_* functions give you ggplots, so you can build upon them using
#ggplot2 layers if you want (added via "+", not "%>%"). ggplot2 will be the
#focus of the next post so don't worry if it doesn't make as much sense to you
#yet
labs(title = "customized density plot")
6.2.4 basic plot_box()
pdata_resampled %>%
plot_box(y1, g, fill = "blue2")
6.2.5 customized plot_box() with facetting
#boxplot showing additional customization
plot_box(data = pdata, #data source
y = y2, #variable to go on the y-axis
x = high_low, #variable on the x-axis
ylab = "y2 score", #custom y-axis label
xlab = "treatment dosage", #custom x-axis label
x_var_order = c("low", "high"),
fill_var = g, #assign variable am to fill
fill_var_title = "group", #relabel the fill variable title in the legend
fill_var_order = c( "c", "a", "b", "d", "e"), #reorder the levels of the colour variable
fill_var_labs = c("control" = "c",
"treatment A" = "a",
"treatment B" = "b",
"treatment D" = "d",
"treatment E" = "e"), #recode the colour variable labels
fill_var_values = c("blue3",
"red3",
"green3",
"purple3",
"gold3"), #change the colours from the ggplot2 defaults
facet_var = d,
theme = "bw") #specify the theme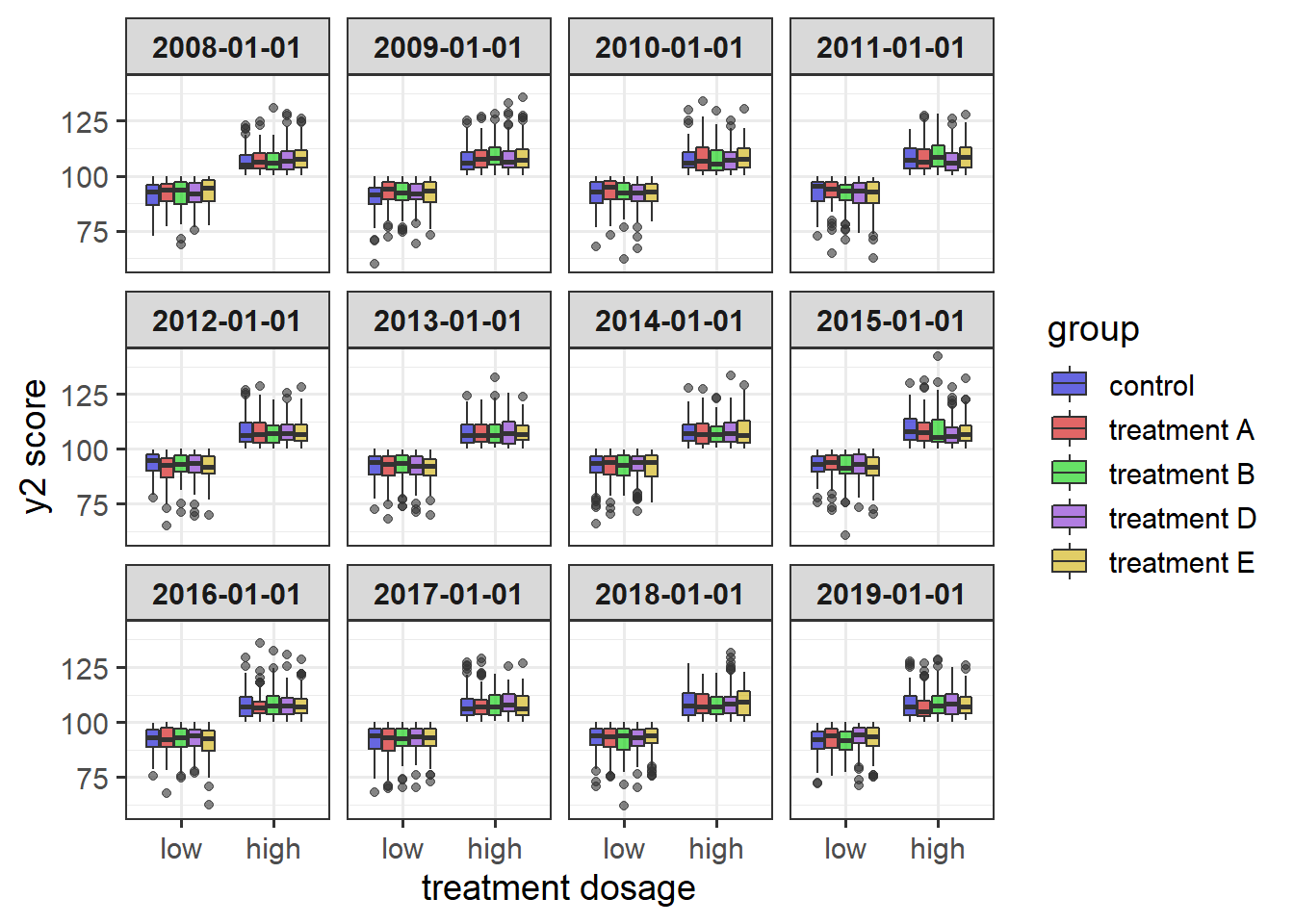
6.2.6 basic plot_stat_error() of the mean +/- SE
#plot a mean with SE error bars
pdata %>%
plot_stat_error(y = y1,
x = g,
fill = "red",
stat = "mean",
error = "se",
theme = "bw")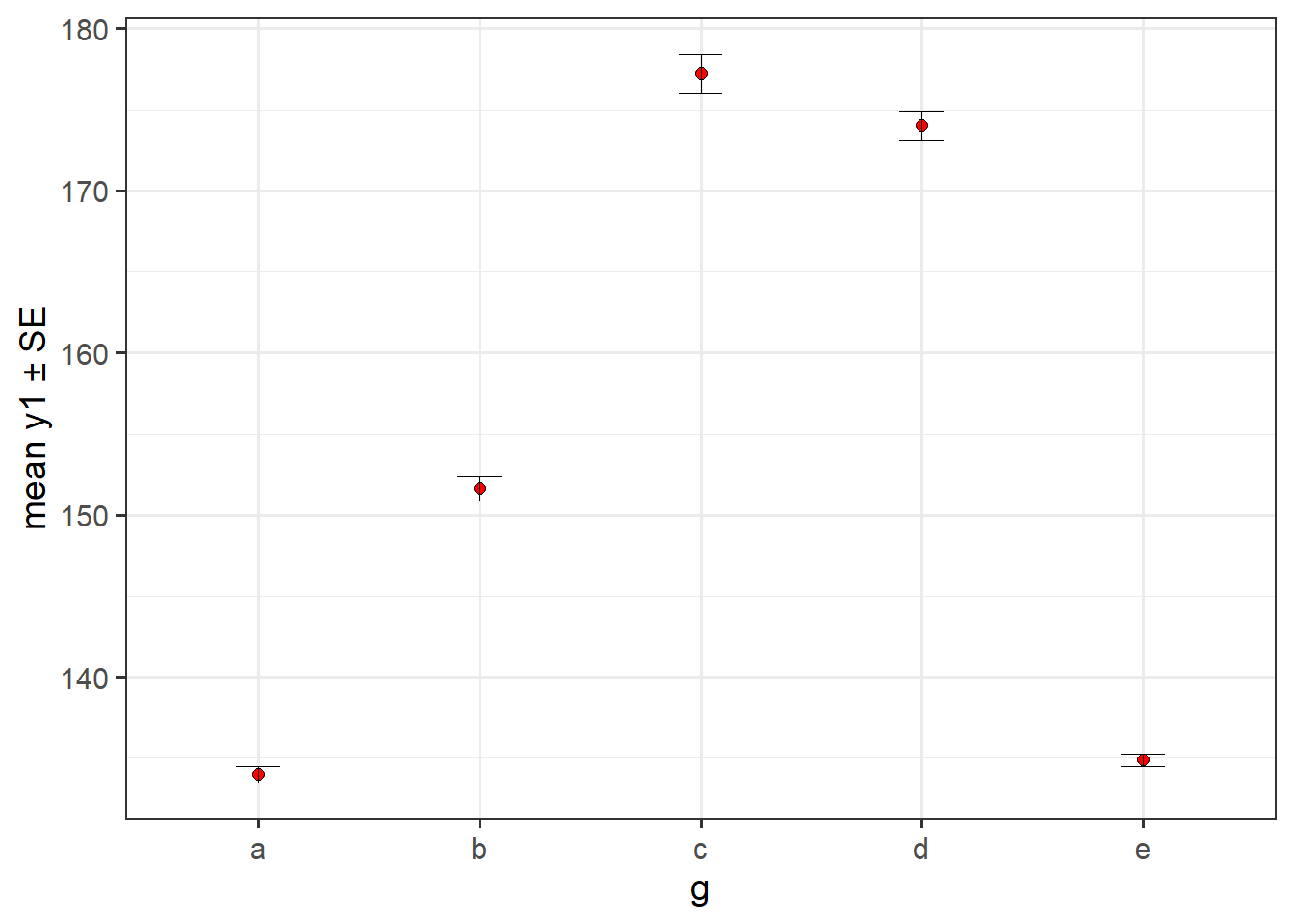
#notice that the y-axis default reflects the specified statistic (mean or
#median) and error metricThis one shows us that the mean y1 scores of groups “c” and “d” are actually a lot higher (over 170) than the mean y1 scores of the other groups with groups “a” and “e” having very similar means around 135 and group “b” falling in between the others at approximately 152. The practical utility of these observed mean differences of course depends on whether or not the distributions are approximately Gaussian. If so, then a plot of the group medians and 95% CIs for them should look similar. However, as shown below, they aren’t (which shouldn’t be a surprise after seeing the density plots above).
6.2.7 plot medians and bootstrapped CIs
#You can also produce a bar graph of group medians with 95% bootstrapped
#confidence interval error bars and easily modify fill, colour, and transparency
pdata[1:100, ] %>%
plot_stat_error(y = y1, x = g,
#in case your supervisor asks for it, you can get bars instead
#of points... although the default points are recommended in
#most cases
geom = "bar",
stat = "median",
fill = "blue2",
colour = "black",
alpha = 0.7,
replicates = 2000) #controls the number of bootstrapped samples to use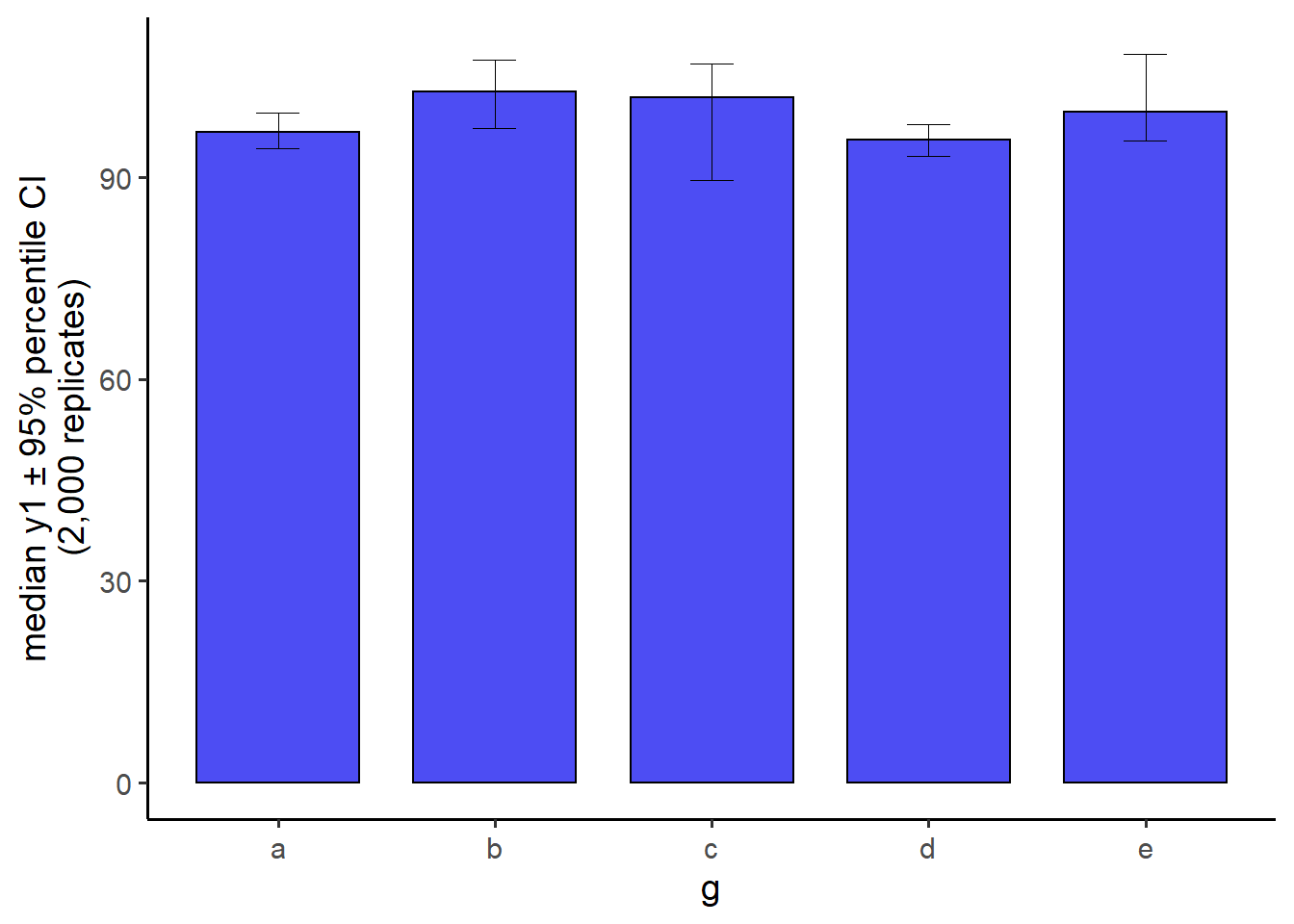
6.2.8 plot means or medians and CIs for multiple time points connected with lines
Overall means and medians can hide important variations in the data in cases where repeated measurements are taken over time. For example, when we account for observation year in pdata by plotting the “d” date column on the x-axis and assigning the “g” factor to colour, there is a clear divergence of group median “y1” scores from 2008-2019 that becomes especially noticeable after 2014.
#an example with "longitudinal" data
pdata %>%
#all dates in the d column are for Jan. 1st. Since only the year is
#meaningful, we'll 1st extract the 1st 4 characters from the d column values
#using a combination of dplyr::mutate() and stringr::str_sub()
mutate(d = as.factor(str_sub(d, end = 4))) %>%
plot_stat_error(y = y1, x = d,
xlab = "year",
stat = "median", #default error metric is a 95% CI
colour_var_title = "group",
colour_var = g,
colour_var_order = c( "c", "a", "b", "d", "e"),
colour_var_labs = c("control" = "c",
"drug A" = "a",
"drug B" = "b",
"drug D" = "d",
"drug E" = "e"), #recode the colour variable labels
colour_var_values = c("blue3",
"red3",
"green3",
"purple3",
"gold3"), #change the colours from the ggplot2 defaults
geom = "point", #either "bar" or "point". default = "point"
p_size = 2, #adjust the size of the points
add_lines = T, #connect the points with lines. This is useful for repeated-measures data.
alpha = 0.6) #adjusts the transparency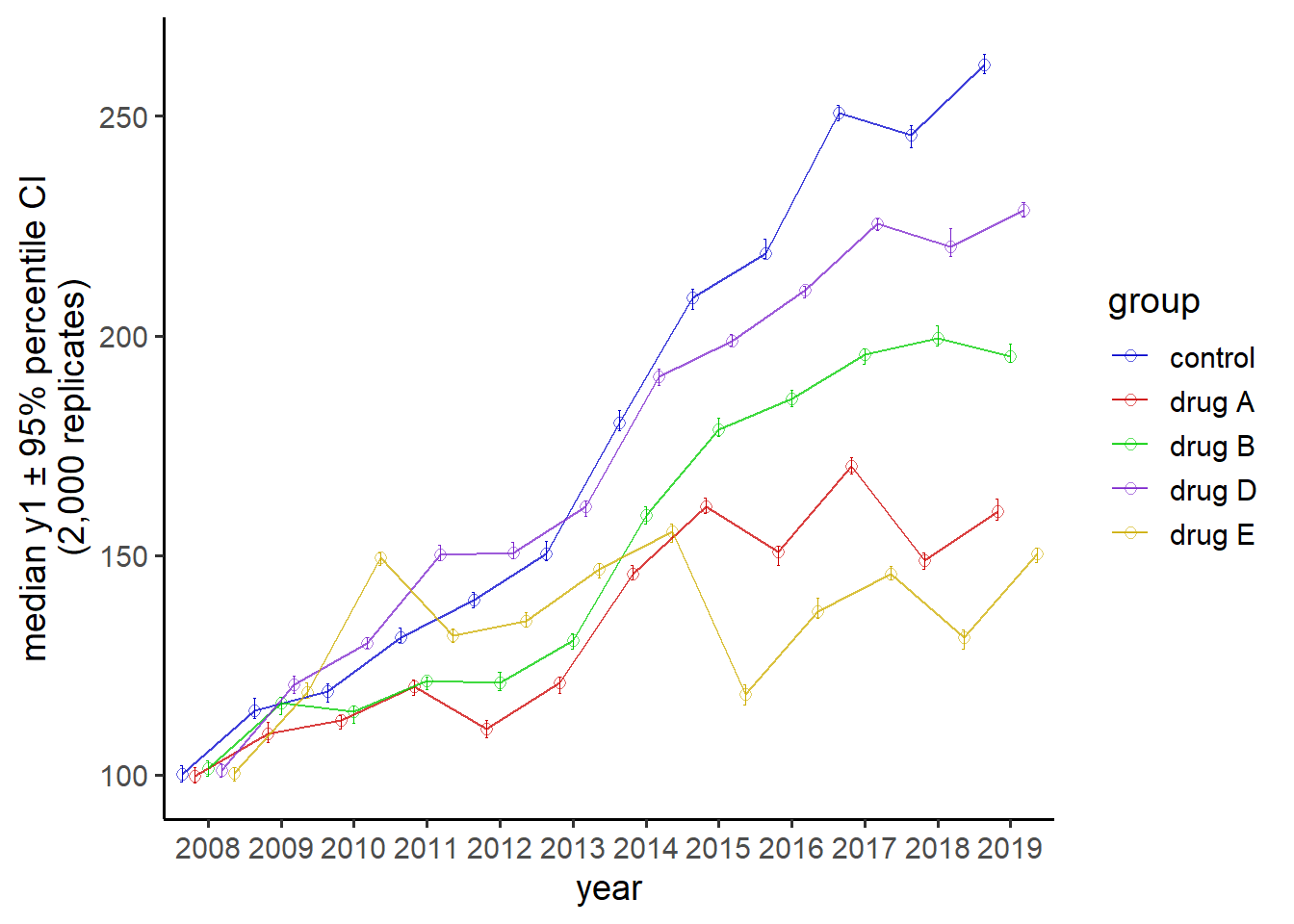
Thus, despite the apparent lack of any “g” factor group differences in median y1 scores that we saw before when plotting the overall medians & CIs, there do appear to be substantial group differences at specific time points which are revealed when time is properly considered.
A number of additional plot_* functions (e.g. plot_bar(), plot_line(), etc.) are in development and will be added to the package as soon as they are ready.
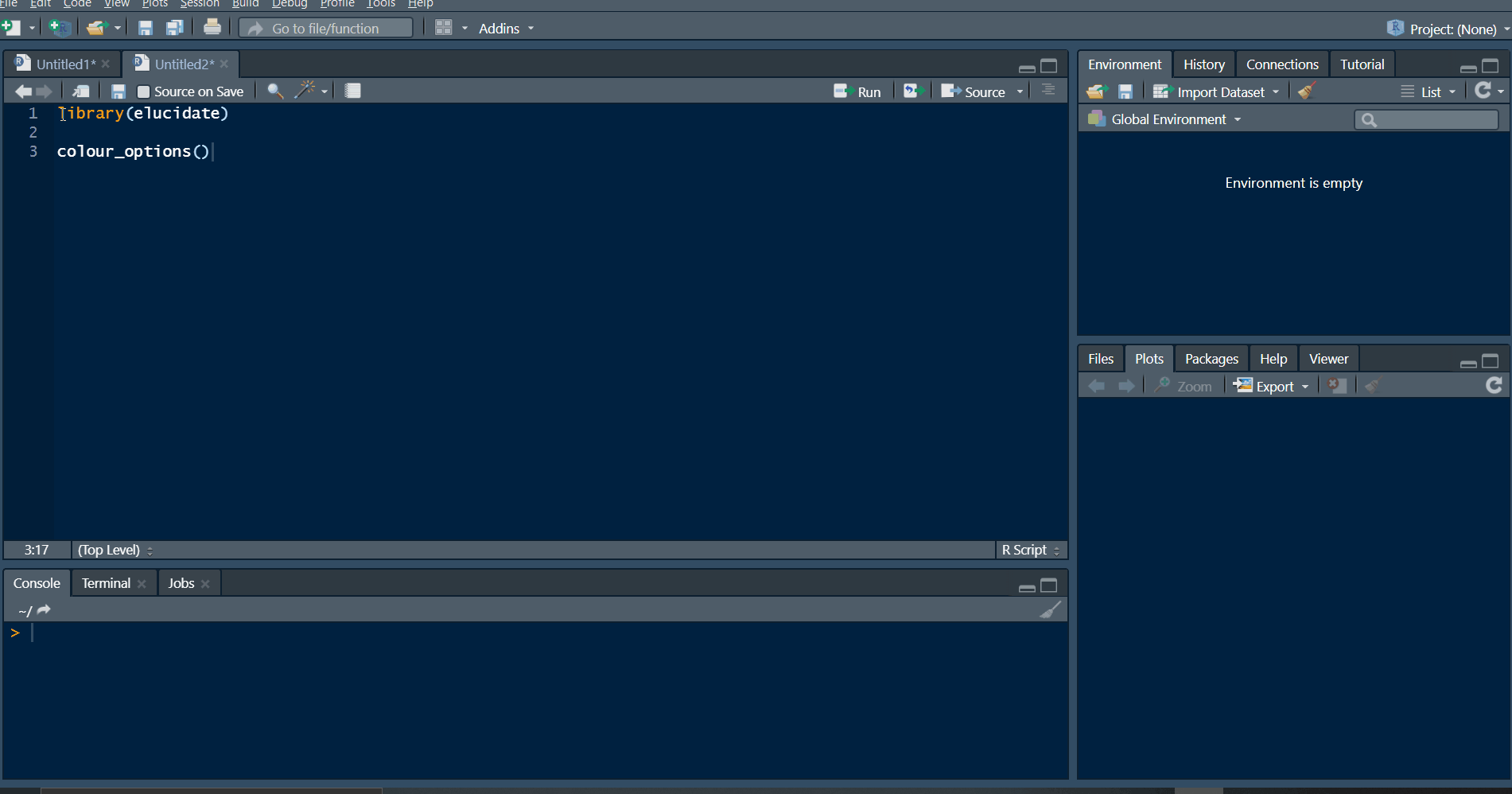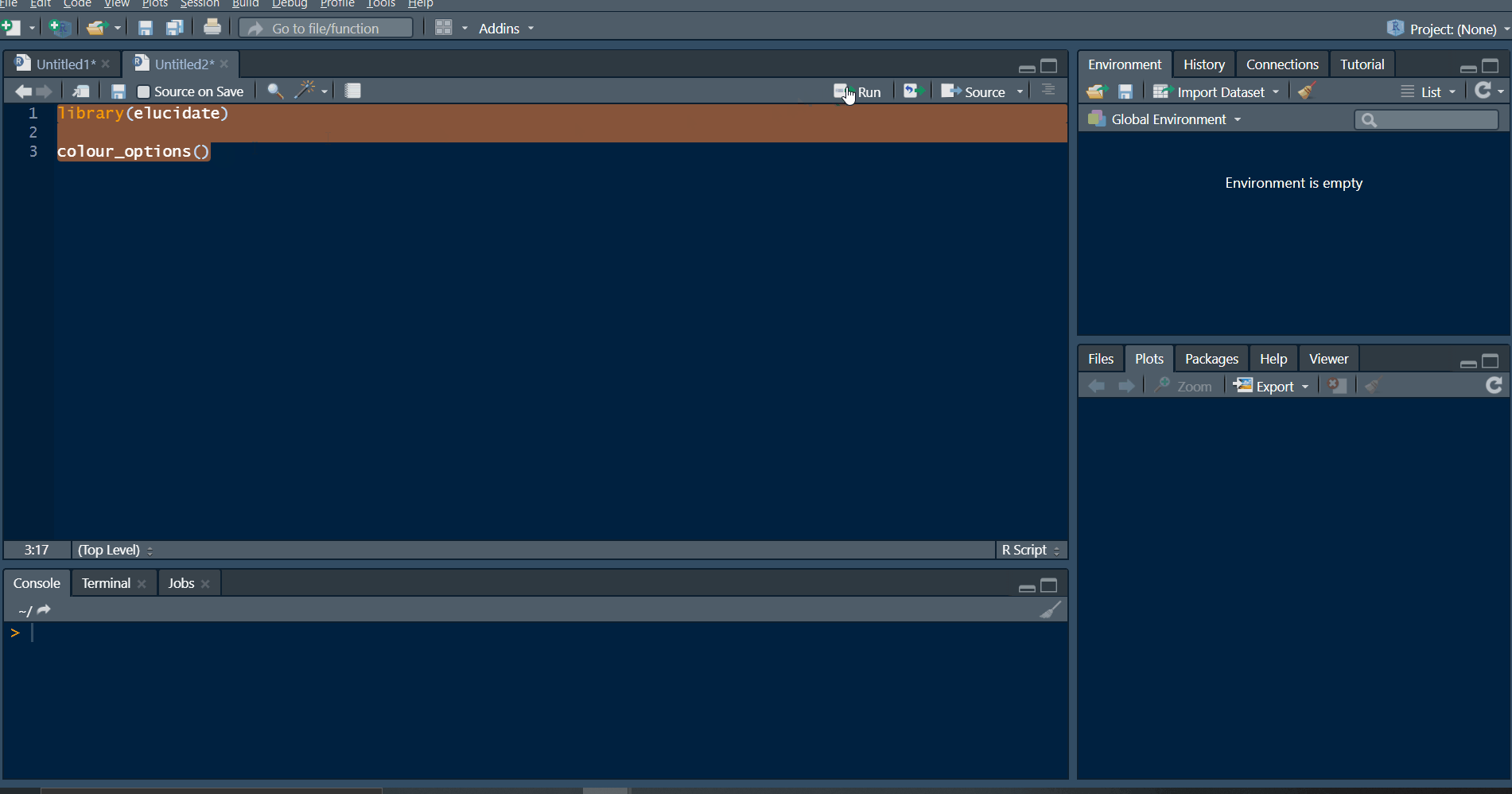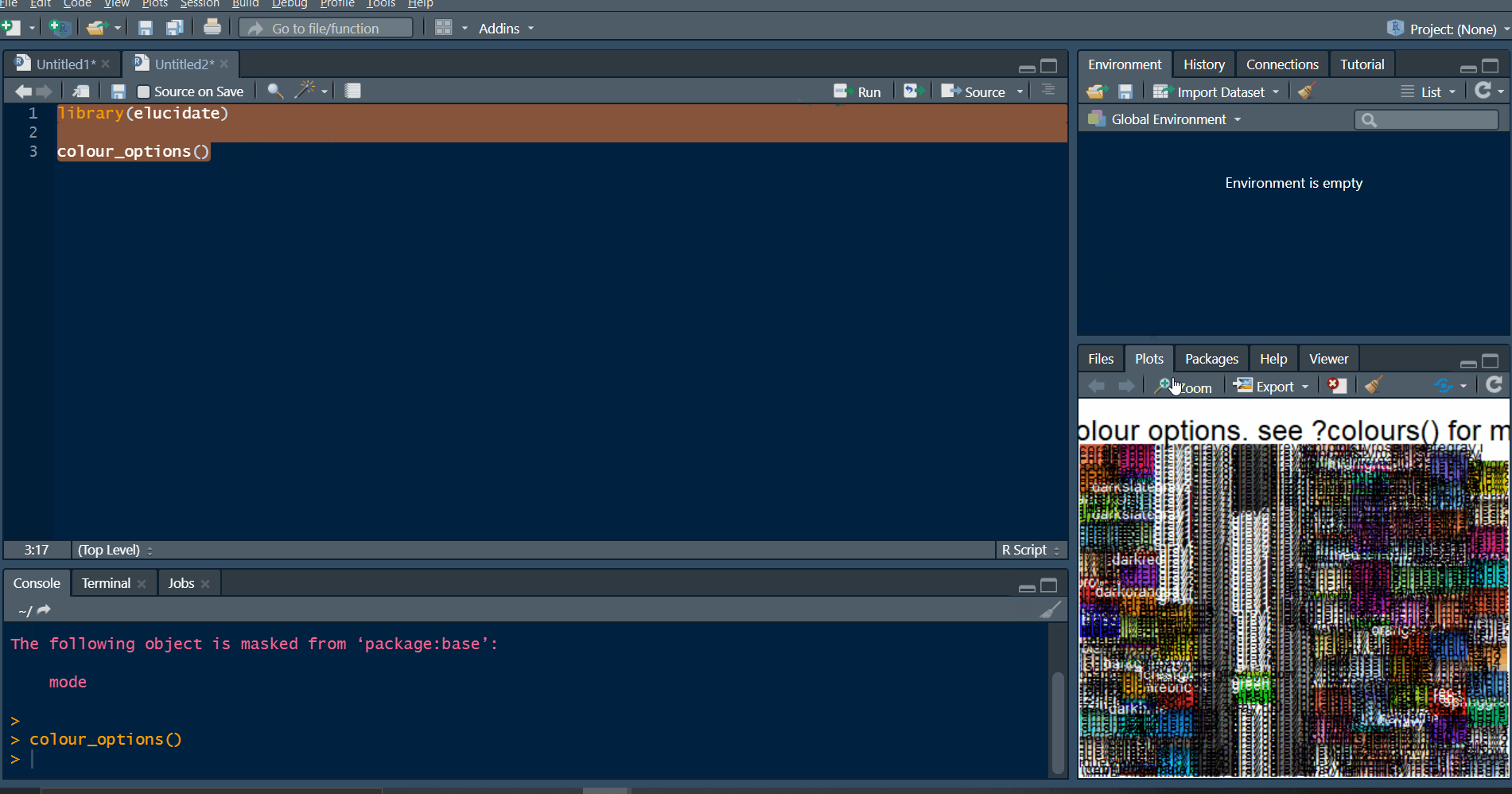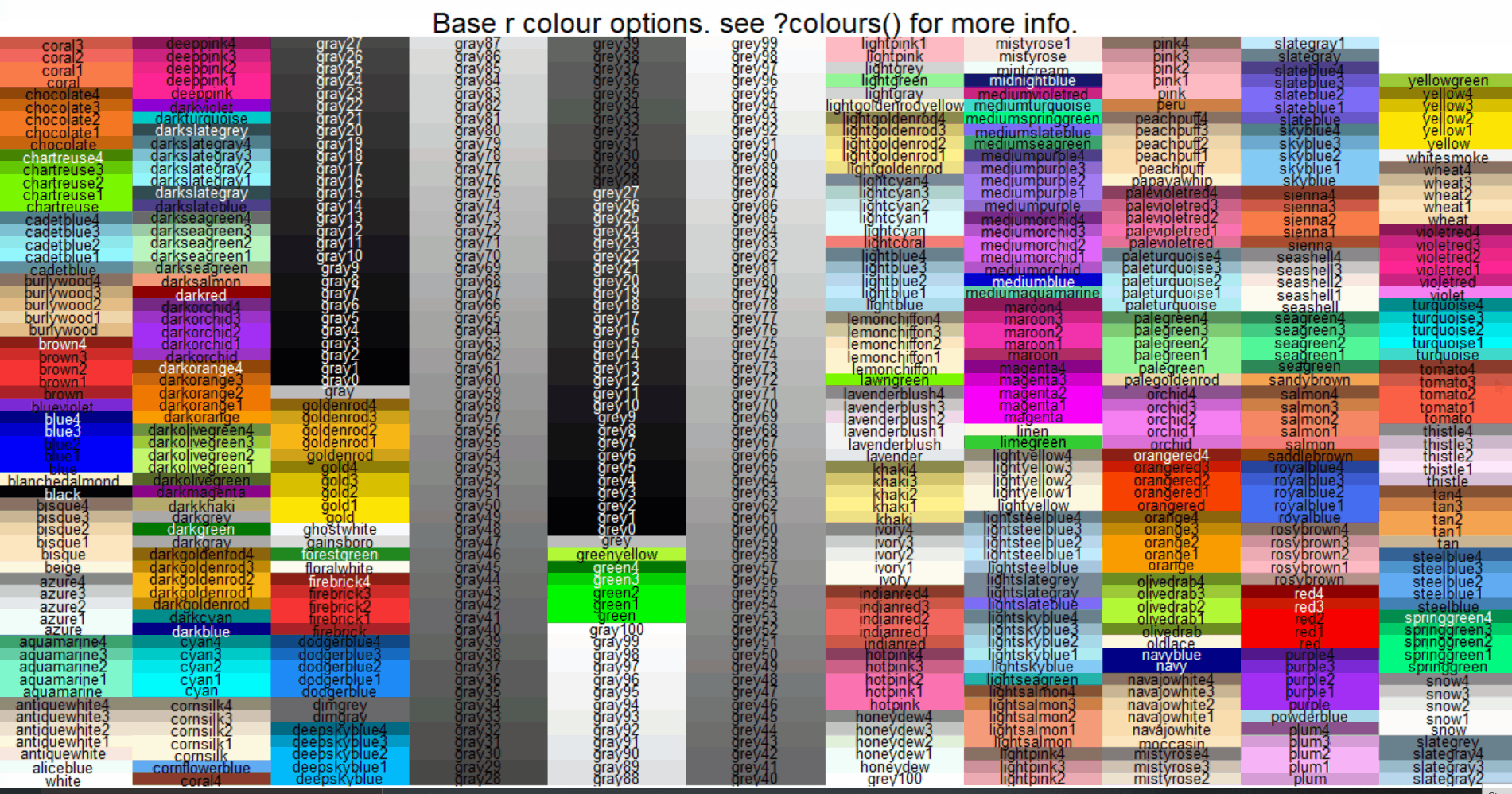
To see what the basic R colour options are (which I’ve found to be more than sufficient for exploratory purposes), you can use eludicate::colour_options(), which renders labeled example tiles of the colours in either the “plot” panel of R studio…
…or saves them to a PDF file in your working directory using the “print_to_pdf” argument (in case you wanted to print it). By default, this PDF will be called “base_r_colour_options.pdf” but you can change it using the “pdf_name” argument.
7 Interacting with dynamic data representations
elucidate::static_to_dynamic() is a convenience wrapper for functions in the DT, reactable and plotly packages that allow you to convert static data frames and ggplot2 graphs into dynamic DataTables/reactables and plotly graphs you can interact with. Output from static_to_dynamic() is displayed in the “Viewer” tab of R studio, rather than the “Plots” tab.
By default, static_to_dynamic() will convert a data frame into a JavaScript “DataTable” via the DT::datatable() function if there are <= 10,000 rows, and a “reactable” via the reactable::reactable()18 function if there are more than 10,000 rows. This is because (in my experience) the current local-processing implementation of datatable() function tends to run slowly (if at all) for data sets that are larger than this threshold, whereas the reactable alternative still works reasonably well with larger data sets (at least 100,000 rows)19.
Either option can be used for data frames with less than 10,000 rows via a
reactableargument (TRUE= “reactable”/FALSE= “DT”, default =FALSE). Both options offer search-based filtering for the entire table or for specific columns, and (multi-)column sorting capabilities.datatable()provides more functionality overall thanreactable(), including Excel-like cell-editing/filling, easier filtering of rows, the ability to rearrange columns by clicking and dragging them, show or hide columns selectively, and options for downloading/copying/printing data. I tend to prefer theDTversion for these features when I’m interacting with smaller tables, like the outputs of thedescribe*functions, but if you find that it is loading too slowly on your machine, try the “reactable” =TRUEargument option instead (which will still be nicer than the base RView()display).
reactable()is faster and more efficient than (locally-processed)datatable’s, so it still works reasonably well for larger datasets.reactable(), but notdatatable()also allows you to group the table by one or more columns with the “group_by” argument so that you can collapse/expand certain groups of interest with a simple click of the mouse. The row stripes and highlighting are more clearly visible in thereactable()version as well, and you can also select multiple rows with check boxes to highlight them which can make visually comparing rows of interest a bit easier.
ggplot2graphs (i.e. the outputs of theplot_*functions) are converted to interactiveplotlygraphs viaplotly::ggplotly(), which lets you pan around the plot, zoom in to different areas of it, highlight a subset of data points, and more.
8 Correct data with wash_df() & recode_errors()
Although, the main focus of elucidate is on data exploration, it has a few auxiliary utility functions, recode_errors() & wash_df(), which help you replace/remove errors & correct common formatting problems detected during the exploration process.
To demonstrate their utility, I’ve prepared a messy version of a subset of the mtcars dataset that we’ve seen before. Imagine, if you will, that these messy data had been supplied by a collaborator for you to analyse and you hadn’t seen another version of them before.
Let’s see what we’re dealing with using a combination of glimpse() , dupes(), counts_tb_all(), and describe_all().
messy_cars %>%
glimpse() %>%
dupes() %>%
head()## No column names specified - using all columns.## Rows: 44
## Columns: 8
## $ `Miles per gallon` <dbl> 21.0, 21.0, 22.8, 21.4, 18.7, 18.1, 14.3, 24.4, 22.~
## $ `# of cylinders` <chr> "six", "six", "4", "six", "8", "six", "8", "4", "4"~
## $ DISP <chr> "160", "160", "108", "258", "N/A", "225", "N/A", "1~
## $ hp <dbl> 110, 110, 93, 110, 175, 105, 245, 62, 95, 123, 123,~
## $ wt <dbl> 2.620, 2.875, 2.320, 3.215, 3.440, 3.460, 3.570, 3.~
## $ gear <chr> "four", "four", "four", "3", "3", "3", "3", "four",~
## $ am <dbl> 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ notes <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,~## Duplicated rows detected! 21 of 44 rows in the input data have multiple copies.## Miles per gallon # of cylinders DISP hp wt gear am notes n_copies
## 1 15.0 8 N/A 999 3.57 5 1 NA 4
## 2 15.0 8 N/A 999 3.57 5 1 NA 4
## 3 15.0 8 N/A 999 3.57 5 1 NA 4
## 4 15.0 8 N/A 999 3.57 5 1 NA 4
## 5 15.5 8 N/A 150 3.52 3 0 NA 3
## 6 15.5 8 N/A 150 3.52 3 0 NA 3glimpse() reveals some inconveniently formatted column names, which (in R) shouldn’t contain spaces or begin with non-letter characters. You also want a column to have consistently formatted values, not like the mix of string and numeric values we are seeing under the number of cylinders column. copies(filter = "dupes") also notifies us that 21 of the 44 rows in messy_cars are not unique.
counts_tb_all(messy_cars, n = 5)## $`Miles per gallon`
## top_v top_n bot_v bot_n
## 1 15 4 13.3 1
## 2 15.2 3 14.3 1
## 3 15.5 3 14.7 1
## 4 19.2 3 15.8 1
## 5 21 3 16.4 1
##
## $`# of cylinders`
## top_v top_n bot_v bot_n
## 1 8 21 six 9
## 2 4 14 4 14
## 3 six 9 8 21
## 4 <NA> <NA> <NA> <NA>
## 5 <NA> <NA> <NA> <NA>
##
## $DISP
## top_v top_n bot_v bot_n
## 1 N/A 17 108 1
## 2 275.8 4 120.1 1
## 3 160 3 120.3 1
## 4 146.7 2 121 1
## 5 167.6 2 140.8 1
##
## $hp
## top_v top_n bot_v bot_n
## 1 110 4 109 1
## 2 150 4 113 1
## 3 175 4 205 1
## 4 180 4 215 1
## 5 999 4 230 1
##
## $wt
## top_v top_n bot_v bot_n
## 1 -1 5 2.14 1
## 2 3.57 5 2.32 1
## 3 3.44 3 2.465 1
## 4 3.52 3 2.77 1
## 5 2.2 2 2.78 1
##
## $gear
## top_v top_n bot_v bot_n
## 1 3 20 4 2
## 2 four 14 5 8
## 3 5 8 four 14
## 4 4 2 3 20
## 5 <NA> <NA> <NA> <NA>
##
## $am
## top_v top_n bot_v bot_n
## 1 0 25 1 19
## 2 1 19 0 25
## 3 <NA> <NA> <NA> <NA>
## 4 <NA> <NA> <NA> <NA>
## 5 <NA> <NA> <NA> <NA>
##
## $notes
## top_v top_n bot_v bot_n
## 1
## 2 <NA> <NA> <NA> <NA>
## 3 <NA> <NA> <NA> <NA>
## 4 <NA> <NA> <NA> <NA>
## 5 <NA> <NA> <NA> <NA>counts_tb_all() tells us that the “# of cylinders” column uses numeric coding for all 4 and 8 cylinder cars but the string “six” for all 6 cylinder cars, a problem that also affects some entries of “four” in the “gears” column. It also shows us an impossible value of “-1” for the car’s weight (“wt”) in 5 cases, 14 invalid N/A values in the “DISP” column (these should be simply NA or missing altogether).
describe_all(messy_cars,
output = "dt") #so all output is printed## $character
## variable cases n na p_na n_unique min_chars max_chars
## 1: # of cylinders 44 44 0 0 3 1 3
## 2: DISP 44 44 0 0 18 2 5
## 3: gear 44 44 0 0 4 1 4
## counts_tb
## 1: 8_21, 4_14, six_9
## 2: N/A_17, 275.8_4, ..., 79_1, 95.1_1
## 3: 3_20, four_14, 5_8, 4_2
##
## $logical
## variable cases n na p_na n_TRUE n_FALSE p_TRUE
## 1: notes 44 0 44 1 0 0 NaN
##
## $numeric
## variable cases n na p_na mean sd se p0 p25 p50
## 1: Miles per gallon 44 44 0 0 20.070 6.169 0.930 10.4 15.20 18.95
## 2: hp 44 44 0 0 214.045 257.074 38.755 52.0 96.50 136.50
## 3: wt 44 44 0 0 2.907 1.585 0.239 -1.0 2.62 3.44
## 4: am 44 44 0 0 0.432 0.501 0.076 0.0 0.00 0.00
## p75 p100 skew kurt
## 1: 22.80 33.900 0.855 0.006
## 2: 180.00 999.000 2.707 6.114
## 3: 3.57 5.424 -1.512 2.195
## 4: 1.00 1.000 0.285 -2.012describe_all() reveals two further problems, a maximum value of 999 (likely representing a data entry error or surrogate value for missingness) under the “hp” column and a completely empty “notes” column. These kinds of inconsistencies and errors are common in datasets where multiple individuals have entered the data manually, e.g. into a shared excel file.
I was the one who messed these data up so I happen to know in this case that “999” and “-1” are erroneous values, but if you see something like this in data that were collected/entered by someone else, you should ask them about it before proceeding.
Fortunately the problems we’re seeing aren’t tough to deal with (for the most part) with a few elucidate helper functions: copies(filter = "first"), wash_df(), and recode_errors().
As you saw earlier, copies(filter = "first") drops the duplicated rows for us, solving one problem. We’ll assign it to a new object, “fixed_cars” which will hopefully converge to the original mtcars data structure as we apply these cleaning functions to it.
fixed_cars <- messy_cars %>% copies(filter = "first")## No column names specified - using all columns.The recode_errors() function accepts a vector of erroneous values to replace with a single value, where the default is NA (but this can be changed via the “replacement” argument). It will also replace “error” argument matches found in any cell in the input data across all rows and columns, but you can limit the search to specific rows or columns by passing a character, logical, or numeric vector of indices to the “rows” and/or “cols” arguments. It accepts a data frame or vector as input, so it also works within dplyr::mutate(). In this case, we can use recode_errors() to fix many of the problems present in messy_cars.
fixed_cars <- fixed_cars %>%
recode_errors(errors = "six", replacement = "6") %>%
recode_errors("four", "4") %>%
#after "data", args. 2 and 3 are "errors" and "replacement"
recode_errors(c(-1, 999),
#default replacement value is NA so we don't need to specify it
cols = c("hp", "wt")) %>% #choose columns to recode
recode_errors("N/A")wash_df() is a convenience wrapper for several functions in the janitor, readr, and tibble packages that help you clean up the formatting of your data and drop empty rows and/or columns. Specifically, by default it will (in this order):
1. Remove completely empty rows and columns using janitor::remove_empty().
2. Convert all column names to “snake_case” format using janitor::clean_names(case = "snake"). The “case” argument allows you to choose a different case to use instead if you want. See the janitor::clean_names() documentation for details.
3. re-parse the classes of all columns in the data with readr::parse_guess(). Such parsing normally happens when you import data using readr::read_csv() and other importing functions, and now you can re-parse the columns on data that are already loaded into R just as easily. This can save you from having to reclassify columns one at a time with the “as.class”-set of functions (as.numeric(), as.character(), etc.).
Each of these operations can also be modified or disabled with wash_df() arguments.
Optionally, you can also convert the row names to a column with the “rownames_to_column” argument, or a column to row names with the “column_to_rownames” argument. These each use tibble package functions with the same names as the wash_df() arguments.
It helps us clean up the messy_cars data by standardizing formatting of column names, dropping the empty “notes” column, and updating the class of the “number_of_cylinders”, “disp”, and “gear” columns from character to numeric to reflect the character-to-numeric value recoding above.
fixed_cars <- fixed_cars %>% wash_df()Let’s see how it turned out by comparison to the relevant columns from the original mtcars data after renaming the “miles_per_gallon” and “number_of_cylinders” columns to match their original mtcars names (“mpg” and “cyl”).
fixed_cars %>%
rename(mpg = miles_per_gallon, cyl = number_of_cylinders) %>% glimpse()## Rows: 32
## Columns: 7
## $ mpg <dbl> 21.0, 21.0, 22.8, 21.4, 18.7, 18.1, 14.3, 24.4, 22.8, 19.2, 17.8,~
## $ cyl <dbl> 6, 6, 4, 6, 8, 6, 8, 4, 4, 6, 6, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 8,~
## $ disp <dbl> 160.0, 160.0, 108.0, 258.0, NA, 225.0, NA, 146.7, 140.8, 167.6, 1~
## $ hp <dbl> 110, 110, 93, 110, 175, 105, 245, 62, 95, 123, 123, 180, 180, 180~
## $ wt <dbl> 2.620, 2.875, 2.320, 3.215, 3.440, 3.460, 3.570, 3.190, 3.150, 3.~
## $ gear <dbl> 4, 4, 4, 3, 3, 3, 3, 4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 4, 4, 4, 3, 3,~
## $ am <dbl> 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0,~select(mtcars, mpg:hp, wt, gear, am) %>% glimpse()## Rows: 32
## Columns: 7
## $ mpg <dbl> 21.0, 21.0, 22.8, 21.4, 18.7, 18.1, 14.3, 24.4, 22.8, 19.2, 17.8,~
## $ cyl <dbl> 6, 6, 4, 6, 8, 6, 8, 4, 4, 6, 6, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 8,~
## $ disp <dbl> 160.0, 160.0, 108.0, 258.0, 360.0, 225.0, 360.0, 146.7, 140.8, 16~
## $ hp <dbl> 110, 110, 93, 110, 175, 105, 245, 62, 95, 123, 123, 180, 180, 180~
## $ wt <dbl> 2.620, 2.875, 2.320, 3.215, 3.440, 3.460, 3.570, 3.190, 3.150, 3.~
## $ gear <dbl> 4, 4, 4, 3, 3, 3, 3, 4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 4, 4, 4, 3, 3,~
## $ am <dbl> 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0,~Not bad. Most aspects match the original, with a couple of mismatches in cases where the “errors” I introduced (N/A, -1, and 999), and then subsequently deleted (set to NA), were meaningful values in the original dataset that I “corrupted” in preparing messy_cars for pedagogical purposes. In this case the true data are available to us for comparison so we could restore the correct values from the uncorrupted backup source. However, in real projects you may be less fortunate and find yourself in the position of having to omit20 anomalous values because doing so interferes less with your ability to get useful results from the data than leaving them in would. Let this example also serve as a lesson of how important it is to be careful with your data at all stages, and back it up, starting on day 1 of collection/entry.
9 Performance Evaluations
To show you how well elucidate functions perform relative to the closest alternatives, we’ll do a few memory utilization and speed comparisons with bench::mark(). For the sake of brevity, we’ll focus on evaluating two of the most computationally demanding elucidate functions: dupes() and describe_all(). We’ll also increase the number of iterations from 10 to 25 for improved benchmarking reliability.
9.1 dupes() vs janitor::get_dupes()
First, I’ll apply dupes() and it’s closest non-elucidate counterpart, janitor::get_dupes(), to pdata_resampled when a couple of search columns are specified and standardize the formatting of the output to show that they yield equivalent results.
a <- dupes(pdata_resampled, d, id) %>%
#remainder of pipeline just serves to standardize the output format
select(d, id, dupe_count = n_copies, everything()) %>%
arrange(d, id, dupe_count) %>%
wash_df()
glimpse(a)## Rows: 1,000,000
## Columns: 11
## $ d <date> 2008-01-01, 2008-01-01, 2008-01-01, 2008-01-01, 2008-01-01~
## $ id <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,~
## $ dupe_count <dbl> 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67,~
## $ g <chr> "e", "e", "e", "e", "e", "e", "e", "e", "e", "e", "e", "e",~
## $ high_low <chr> "high", "high", "high", "high", "high", "high", "high", "hi~
## $ even <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FAL~
## $ y1 <dbl> 106.2633, 106.2633, 106.2633, 106.2633, 106.2633, 106.2633,~
## $ y2 <dbl> 117.9265, 117.9265, 117.9265, 117.9265, 117.9265, 117.9265,~
## $ x1 <dbl> 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59,~
## $ x2 <dbl> 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116,~
## $ x3 <dbl> 248, 248, 248, 248, 248, 248, 248, 248, 248, 248, 248, 248,~b <- get_dupes(pdata_resampled, d, id) %>%
wash_df()
all.equal(a, b)## [1] TRUEGood, now we can use bench::mark() to compare the performance of dupes() to
janitor::get_dupes() when checking for duplicates based on a single variable (column “d” in this case).
bm <- bench::mark(
dupes(pdata_resampled, d),
get_dupes(pdata_resampled, d),
iterations = 25,
check = FALSE
#we won't check for equal output structures here so the other formatting
#steps from before don't need to be included in the timing
)
bm %>%
select(expression, median, mem_alloc)## # A tibble: 2 x 3
## expression median mem_alloc
## <bch:expr> <bch:tm> <bch:byt>
## 1 dupes(pdata_resampled, d) 106ms 142MB
## 2 get_dupes(pdata_resampled, d) 119ms 184MBplot(bm)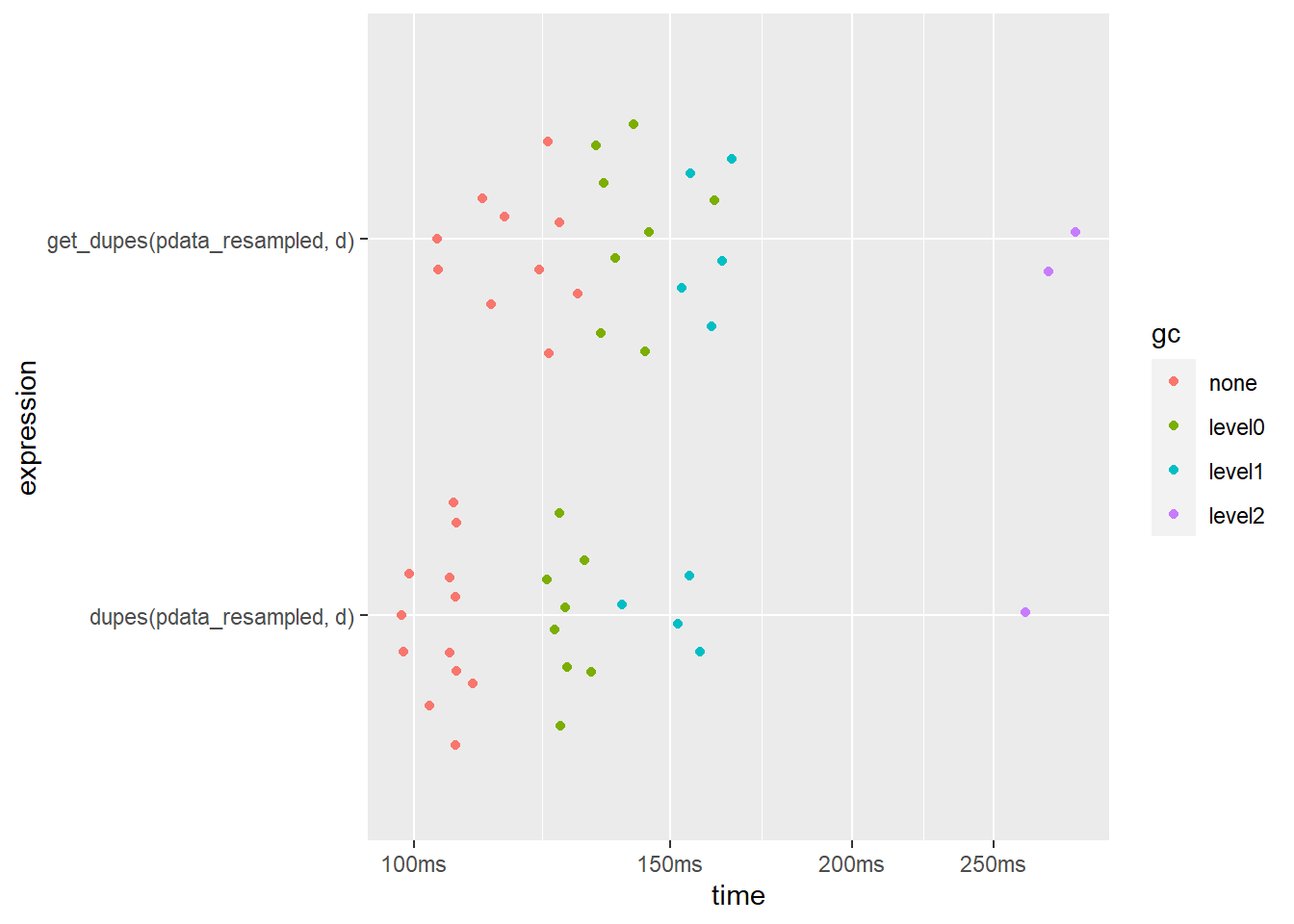
dupes() is slightly faster when only checking 1 column. It also uses less memory.
N.B. If you’re working with a very large dataset you can speed things up quite a bit by setting the dupes() function’s “sort_by_copies” argument to FALSE to skip the time-consuming sorting step…
bm <- bench::mark(
dupes(pdata_resampled, d,
sort_by_copies = FALSE), #disable sorting by duplicates to maximize speed
get_dupes(pdata_resampled, d),
iterations = 25,
check = FALSE
#we won't check for equal output structures here so the other formatting
#steps from before don't need to be included in the timing
)
bm %>%
select(expression, median, mem_alloc)## # A tibble: 2 x 3
## expression median mem_alloc
## <bch:expr> <bch:tm> <bch:byt>
## 1 dupes(pdata_resampled, d, sort_by_copies = FALSE) 61.8ms 130MB
## 2 get_dupes(pdata_resampled, d) 116.7ms 184MBplot(bm)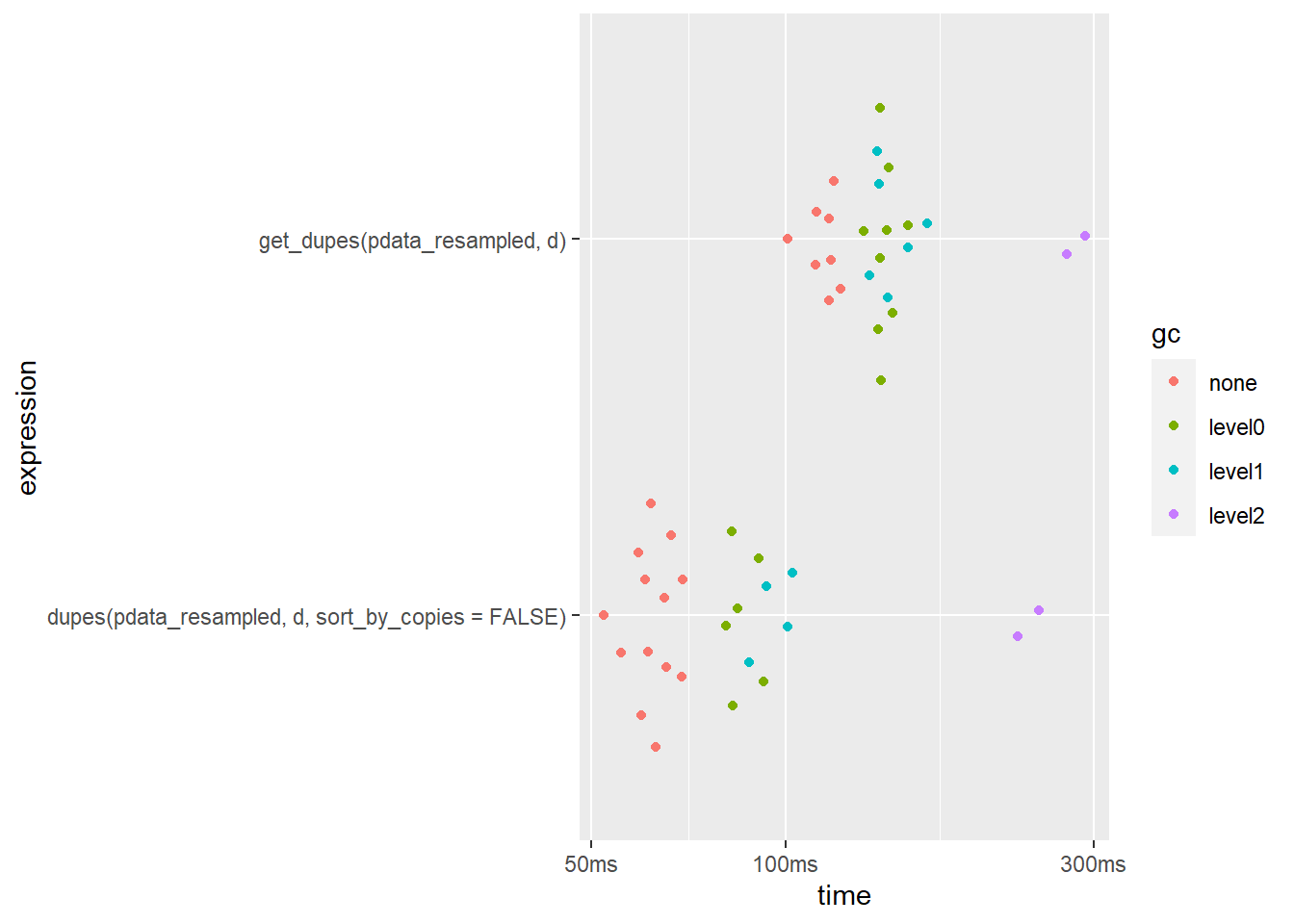
This reduces the median run time of dupes() by around 40% in this case. As far as I am aware, there isn’t a similar option for get_dupes().
What happens when we try to search for duplicates using more than one column?
bm2 <- bench::mark(
dupes(pdata_resampled, high_low, g),
get_dupes(pdata_resampled, high_low, g),
iterations = 25,
check = FALSE
)
bm2 %>%
select(expression, median, mem_alloc)## # A tibble: 2 x 3
## expression median mem_alloc
## <bch:expr> <bch:tm> <bch:byt>
## 1 dupes(pdata_resampled, high_low, g) 74.74ms 143MB
## 2 get_dupes(pdata_resampled, high_low, g) 1.18s 184MBplot(bm2)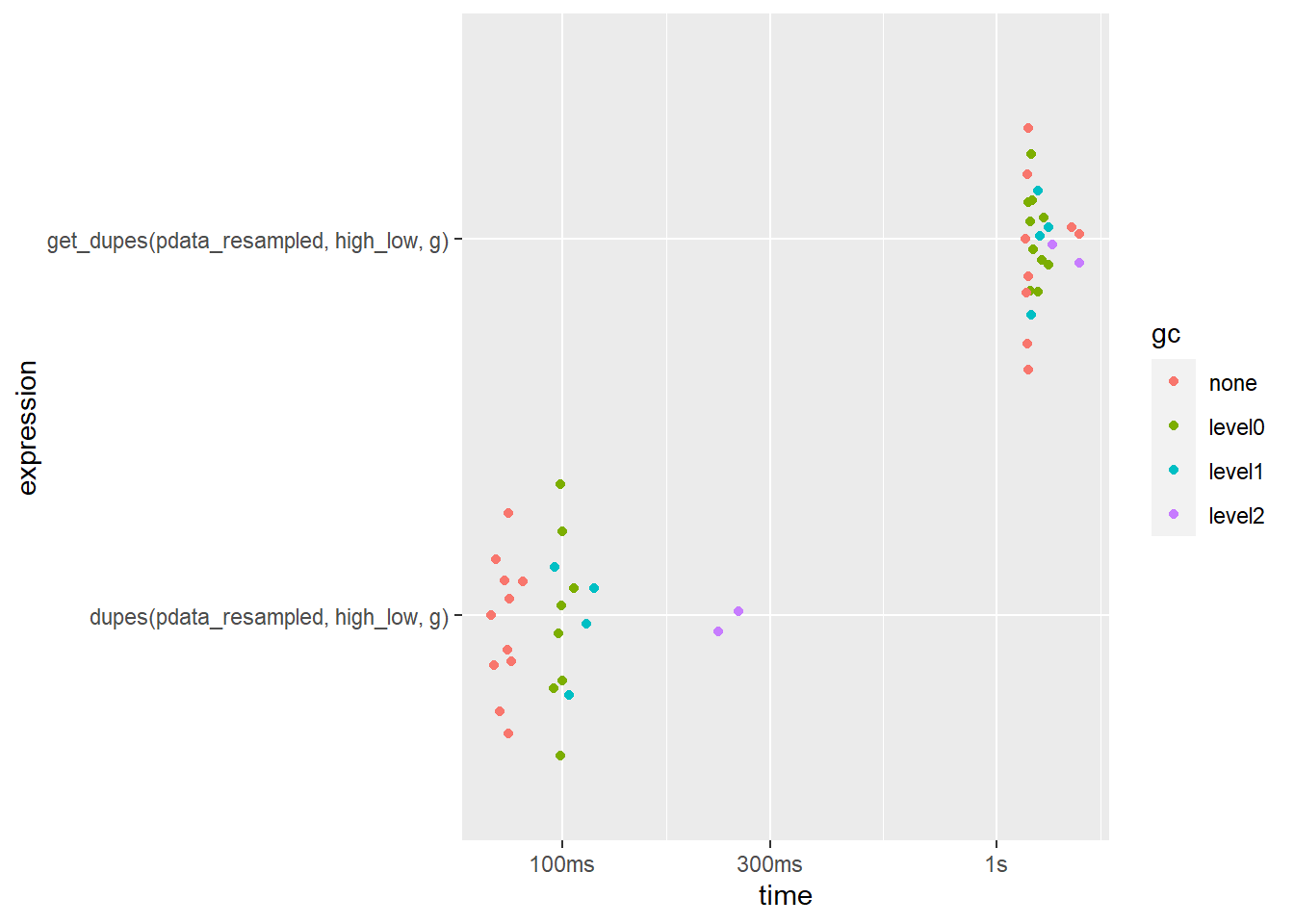
Now the difference is much more noticeable (~64 milliseconds vs. ~1.1 seconds; over a 17-fold speedup in favour of dupes()!) and dupes() still uses less memory.
What if we condition the search upon all 10 columns (the default behaviour for each function if no variables are specified to base the search on using the ... argument)?
bm3 <- bench::mark(
dupes(pdata_resampled),
get_dupes(pdata_resampled),
iterations = 25,
check = FALSE
)
bm3 %>%
select(expression, median, mem_alloc) ## # A tibble: 2 x 3
## expression median mem_alloc
## <bch:expr> <bch:tm> <bch:byt>
## 1 dupes(pdata_resampled) 175.72ms 142MB
## 2 get_dupes(pdata_resampled) 2.09s 237MBplot(bm3)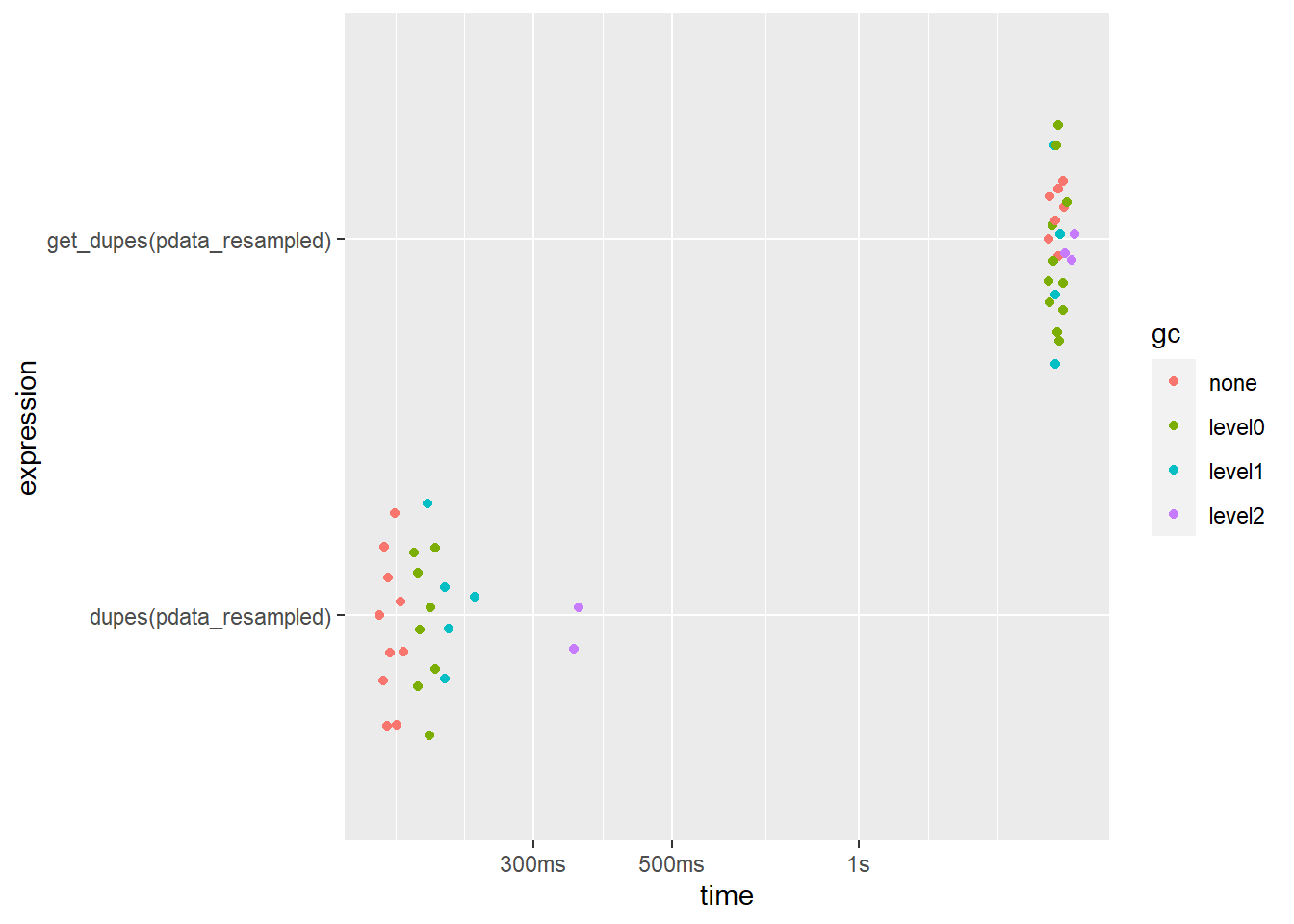
Here the speed difference is smaller but dupes() is still over an order of magnitude faster. get_dupes() also uses more memory but, surprisingly, dupes() doesn’t at all.
9.2 describe_all() vs. skimr::skim()
The only other R function that I’m aware of which is comparable to describe_all() is skimr::skim(). To describe multiple columns of a data frame within each level of a grouping variable with skim(), we need to pass it through a dplyr::group_by() layer first. To simplify the output a bit we’ll just start with “g” as a grouping variable.
I’ll start by showing you what the output of skim() looks like.
pdata_resampled %>%
select(g, y1, d, even) %>% #just to limit printed output
group_by(g) %>%
skimr::skim()| Name | Piped data |
| Number of rows | 1000000 |
| Number of columns | 4 |
| _______________________ | |
| Column type frequency: | |
| Date | 1 |
| logical | 1 |
| numeric | 1 |
| ________________________ | |
| Group variables | g |
Variable type: Date
| skim_variable | g | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|---|
| d | a | 0 | 1 | 2008-01-01 | 2019-01-01 | 2014-01-01 | 12 |
| d | b | 0 | 1 | 2008-01-01 | 2019-01-01 | 2013-01-01 | 12 |
| d | c | 0 | 1 | 2008-01-01 | 2019-01-01 | 2014-01-01 | 12 |
| d | d | 0 | 1 | 2008-01-01 | 2019-01-01 | 2014-01-01 | 12 |
| d | e | 0 | 1 | 2008-01-01 | 2019-01-01 | 2013-01-01 | 12 |
Variable type: logical
| skim_variable | g | n_missing | complete_rate | mean | count |
|---|---|---|---|---|---|
| even | a | 0 | 1 | 0.50 | FAL: 109047, TRU: 107011 |
| even | b | 0 | 1 | 0.56 | TRU: 115207, FAL: 90112 |
| even | c | 0 | 1 | 0.42 | FAL: 106647, TRU: 78088 |
| even | d | 0 | 1 | 0.55 | TRU: 108896, FAL: 88888 |
| even | e | 0 | 1 | 0.47 | FAL: 104644, TRU: 91460 |
Variable type: numeric
| skim_variable | g | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|---|
| y1 | a | 0 | 1 | 133.98 | 25.75 | 75.86 | 112.24 | 132.56 | 156.23 | 202.22 | ▂▇▆▆▁ |
| y1 | b | 0 | 1 | 151.62 | 37.83 | 74.35 | 117.82 | 145.74 | 187.91 | 247.29 | ▃▇▃▇▁ |
| y1 | c | 0 | 1 | 177.35 | 57.00 | 77.02 | 126.68 | 165.83 | 232.25 | 289.24 | ▅▇▃▆▅ |
| y1 | d | 0 | 1 | 174.25 | 43.79 | 69.22 | 137.83 | 175.44 | 214.06 | 268.21 | ▂▆▆▇▂ |
| y1 | e | 0 | 1 | 134.81 | 18.61 | 75.10 | 122.66 | 136.63 | 148.35 | 186.97 | ▁▃▇▇▁ |
Next, I’ll evaluate the performance of both functions using the factor “g” as a grouping variable and requesting descriptions of the other 9 columns in pdata_resampled.
bm1 <- mark(
#describe_all() version
describe_all(pdata_resampled, g),
#skimr::skim() version
skimr::skim(group_by(pdata_resampled, g)),
iterations = 25,
#the output isn't exactly the same so we disable the check argument
check = FALSE)## Warning: Some expressions had a GC in every iteration; so filtering is disabled.bm1 %>%
select(expression, median, mem_alloc)## # A tibble: 2 x 3
## expression median mem_alloc
## <bch:expr> <bch:tm> <bch:byt>
## 1 describe_all(pdata_resampled, g) 1.91s 1.32GB
## 2 skimr::skim(group_by(pdata_resampled, g)) 2.41s 2.12GBbm1 %>% plot()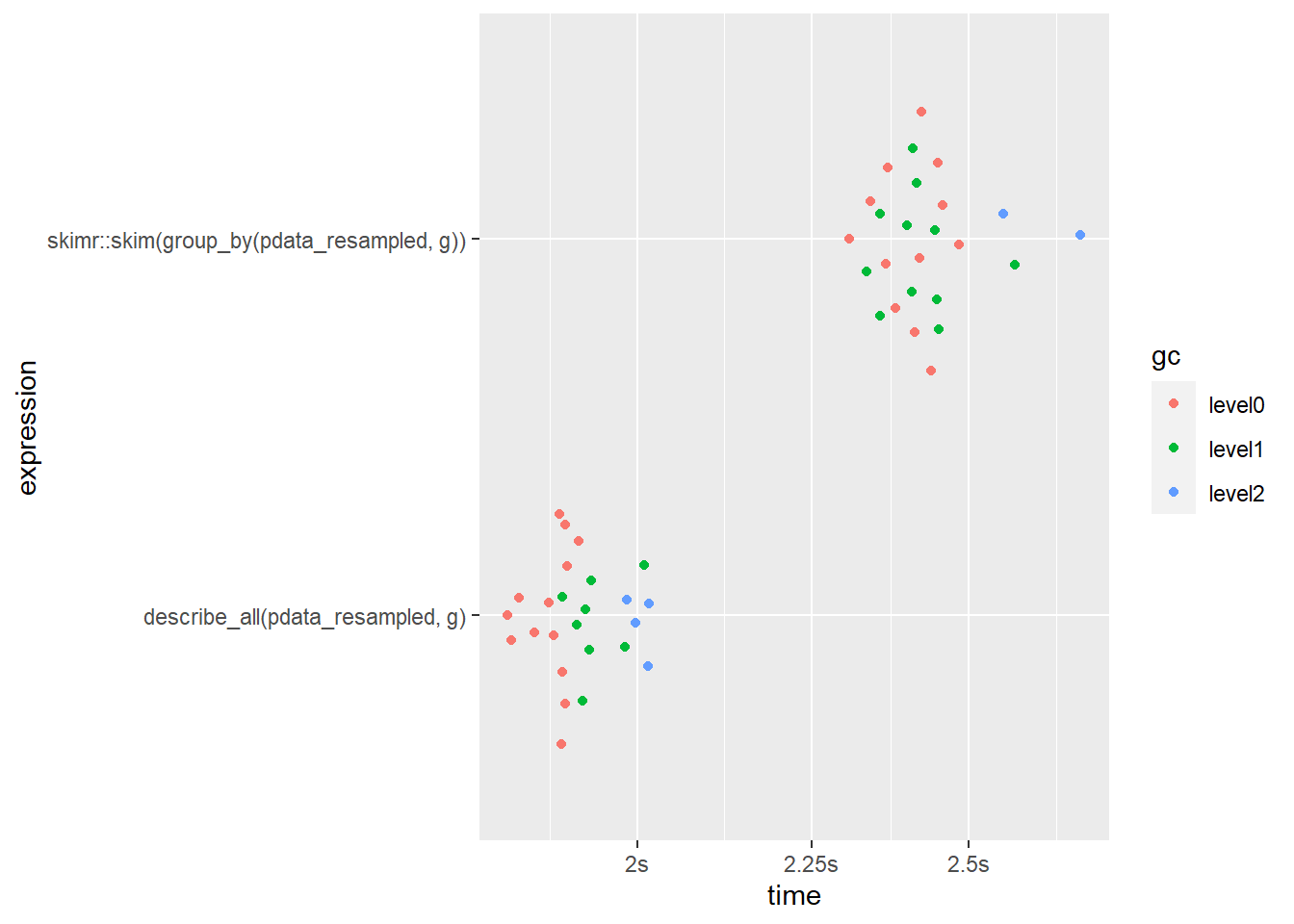
Aesthetically, skim() does give us some nicely formatted & stylish output when used in R markdown 21, but we could achieve something similar by simply passing the outputs of describe* functions to static_to_dynamic().
In terms of performance, we can see that describe_all() runs ~28% faster and uses ~60% less memory when a grouping variable with a handful of levels is specified (similar in terms of scale to most experimental designs with a few treatment groups). describe_all() also gives you more information (for numeric variables: se, skew, kurtosis, proportion of values that are missing). skim() does produce in-line mini-histograms for numeric variables, but I find the resolution of these to be too low to be useful and opt to instead rely on a combination of skewness, kurtosis, and dedicated plotting functions.
What about a situation where you want to split the descriptive summary by more than one grouping variable? When we ask for a description of pdata_resampled grouped by both “g” and “d” with a total of 60 level combinations, now the speed gap between skim() and describe_all() has shifted to a 5% advantage in favour of skim(), although describe_all() is still using substantially less RAM. This result suggests that skim() may scale better in terms of speed, but not memory efficiency, for situations when you need to describe a very large number of groups/partitions (e.g. splitting by many geographic areas like the thousands of US zip codes).
bm1 <- mark(
describe_all(pdata_resampled, d, g),
skimr::skim(group_by(pdata_resampled, d, g)),
iterations = 25,
check = FALSE) #the output isn't exactly the same so we disable the check argument## Warning: Some expressions had a GC in every iteration; so filtering is disabled.bm1 %>%
select(expression, median, mem_alloc)## # A tibble: 2 x 3
## expression median mem_alloc
## <bch:expr> <bch:tm> <bch:byt>
## 1 describe_all(pdata_resampled, d, g) 2.52s 1.29GB
## 2 skimr::skim(group_by(pdata_resampled, d, g)) 2.44s 1.99GBbm1 %>% plot()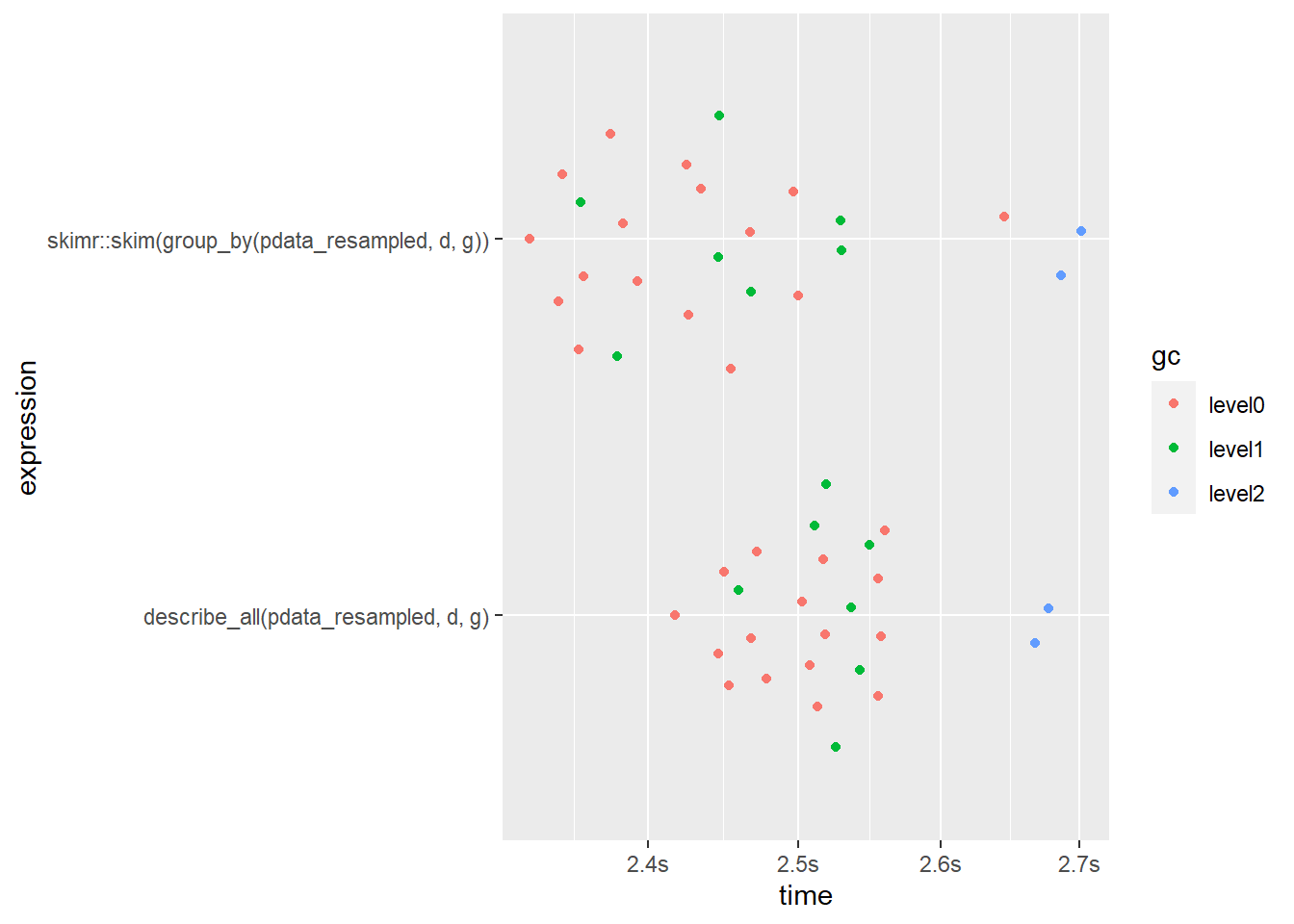
What about the non-grouped version that you’ll probably use most often?
bm1 <- mark(
describe_all(pdata_resampled),
skimr::skim(pdata_resampled),
iterations = 25,
check = FALSE) #the output isn't exactly the same so we disable the check argument## Warning: Some expressions had a GC in every iteration; so filtering is disabled.bm1 %>%
select(expression, median, mem_alloc)## # A tibble: 2 x 3
## expression median mem_alloc
## <bch:expr> <bch:tm> <bch:byt>
## 1 describe_all(pdata_resampled) 1.73s 1.33GB
## 2 skimr::skim(pdata_resampled) 2.1s 2.04GBbm1 %>% plot()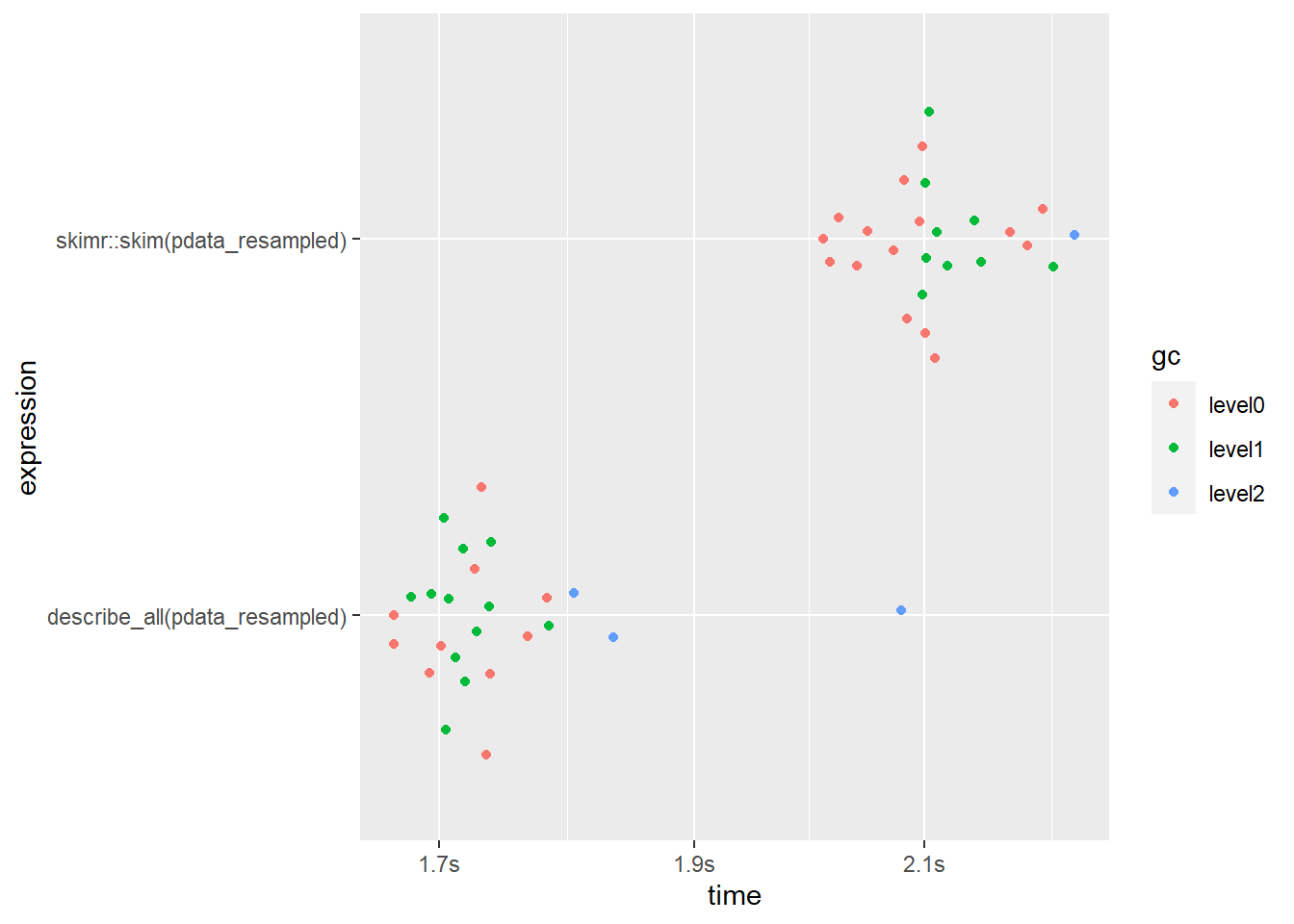
Here describe_all() clearly comes out on top again, finishing ~22% faster and using ~53% less RAM than skim().
That’s it! Hopefully you’ll find that elucidate makes exploratory data analysis in R a breeze when you try it out for yourself.
11 Notes
I acknowledge and express my deep gratitude to the many authors of the tidyverse packages, data.table, and the functions of other dependency packages which were used to build
elucidate, since without their effort and ingenuityelucidatewould mostly have remained a collection of ideas instead of functions.There is one other major component of
elucidatescheduled to be developed starting sometime next quarter, which will facilitate clustering and dimensionality reduction (i.e. unsupervised machine learning), via aprofile*set of functions. After that component has been successfully integrated we’ll try to submit the package to CRAN. I look forward to writing another blog post about those new functions when they’re ready 😄.
Thank you for visiting my blog. I welcome any suggestions for future posts, comments or other feedback you might have. Feedback from beginners and science students/trainees (or with them in mind) is especially helpful in the interest of making this guide even better for them.
This blog is something I do as a volunteer in my free time. If you’ve found it helpful and want to give back, coffee donations would be appreciated.
R (or python) programming really is one of those transferable research skills that eventually does pay 💰 if you stick with it… on top of all the time you’ll find yourself saving by “automating the boring stuff”. If you’re currently a grad student, you can learn about some of the other highly marketable skills you’re developing here.↩︎
R markdown is what I’m using to write these posts, you’ll learn much more about it when we get to the reporting & communication part of the guide↩︎
The “copy_number” column is only provided for the default filter = “all” version of
copies(), since this is when knowing the specific copy number is most useful (i.e. to facilitate subsequent subsetting). Following similar logic, the “n_copies” column is only provided when the filter argument is set to “all” or “dupes” because the other options (“first”, “last”, and “unique”) drop all rows with more than one copy, meaning that the “n_copies” column would contain only values of 1.↩︎The sorting occurs in descending order.↩︎
If you only want the truly unique/non-duplicated rows instead use
copies(data, filter = "unique")↩︎in case you’re wondering, yes, dplyr does have a function called
distinct()that does the same thing ascopies(filter = "first"), although the underlying code is different and it is less flexible↩︎or ascending frequency if you prefer, via the “order” argument↩︎
It is worth noting that
elucidate::mode()masks amode()function in base R which is merely a shortcut for thestorage.mode()function that has nothing to do with tabulating values. Although I usually try to avoid such conflicts, I suspect thatelucidateusers who are primarily analysing data would prefer a tabulatingmode()function.↩︎These are particularly common in psychological research, for example if you test individuals using questions that are too easy or too difficulty. Ceiling and floor effects are also why most university professors who teach tend to be concerned if the class average deviates too far from ~67%↩︎
The base R
quantile()function can be used to get percentiles, i.e. the value of the vector below which are “x”% of the other values in that vector. In case you ever happen to want to find out which percentile a value is, instead of the value at a specified percentile, elucidate provides aninv_quantile()function that gives you the inverse or opposite ofquantile(). This could be useful if you are a teacher and want to know how some students with scores “x”, “y”, & “z” rank in the class, or in case a student asks you how well they performed on a test relative to the their peers.↩︎However, unlike the equivalent functions in other packages, the
elucidateversion’s default setting for each of these is type 2 because it is unbiased under normality, and to a lesser extent for consistency with SAS & SPSS↩︎This great performance comes from the wonderful data.table package doing the bulk of the heavy lifting for us under the hood.↩︎
Efron, B., & Tibshirani, R. J. (1994). An introduction to the bootstrap. CRC press.↩︎
“Independent and identically distributed” means that the value of one observation is completely independent from the values of other observations in the sample. This is another assumption of most common (frequentist) parametric tests, like the t-test, which is referred to as the “independence assumption”. We’ll learn how to evaluate it in a future post on model diagnostics.↩︎
Parallelisation for bootstrapping with the
elucidate::*_cifunctions uses the “snow” (multi-session) method for Windows machines (as the only option available) and the faster “multicore” (forking) method for non-Windows machines. Thedescribe_ci()function checks which OS you are using and chooses the correct one for you via the underlyingboot::boot()function’s “parallel” argument. See the?boot()documentation for additional details.↩︎thanks to the thoughtful authors of the
ggplot2package, which I’ll dive into in the next post↩︎Since this post was originally written,
plot_pie()andplot_bar()have been added toelucidateto make it easier to generate pie charts and bar graphs. Of the two, a bar graph is nearly always better at presenting the same information, butplot_pie()is available in case your boss asks for a pie chart anyways.↩︎N.B. For the reactable version to work properly, you’ll need to have the reactable and shiny packages installed. These packages are currently “suggested” instead of “required” as dependencies to limit the number of installation requirements for
elucidate↩︎There is a server-side processing option available for use with
datatable()specifically designed to use with bigger data, but sending your data to be processed on a server isn’t a usually a viable option when you’re working with sensitive or proprietary information (unless you have a private server of course), so it has not been implemented instatic_to_dynamic().↩︎Other strategies for dealing with missing values will be the topic of a future blog post.↩︎
R markdown is what these blog posts are written in; the
skim()output looks different when printed from a regular R script.↩︎